
Lors d’une migration SEO avec changement d’URL, de nombreuses tâches doivent être mises en place pour faciliter le passage des URL de l’ancien au nouvel intitulé. Plusieurs outils peuvent grandement vous faciliter le travail en automatisant un certain nombre d’étapes, et en passant par des méthodes de scraping (analyse du contenu et détection de certaines séquences) de vos pages. Voici comment…
 Par Aymeric Bouillat
Par Aymeric BouillatPrincipe d’une migration SEO
Lors d’une refonte de site, et en cas de modification de la structure des URL, il est indispensable de rediriger les anciennes URL vers les nouvelles, via des redirections de type 301. Cela permettra d’une part de transférer la popularité acquise par les landing pages SEO du site vers les nouvelles URL, et cela limitera d’autre part le nombre d’erreurs 404, permettant ainsi à Googlebot d’être efficace dans l’utilisation du temps machine consacré à votre site par ses robots.
Grâce à ces redirections, l’essentiel des positions pourra être conservé, voire amélioré si vous profitez de la migration pour faire le ménage et corriger les problèmes de duplication de contenu par exemple.
Pages sans correspondances
Lors de l’inventaire des URL à migrer en fonction de différents critères, que ce soit les clics / impressions dans les pages de résultat, ou encore les URL recevant des liens externes, certaines d’entre elles n’ont pas forcément de correspondance sur le nouveau site.
Cela peut se produire sur les sites de e-commerce pour les produits qui ne sont pas renouvellés (ou qui sont en rupture de stock de façon définitive), mais également pour des pages catégories en cas de restructuration de l’arborescence (ex : regroupement de catégories, suppression de la catégorie « Petit electroménager »). Ces URL ayant parfois un potentiel SEO non négligeable, doivent être redirigées pour les plus performantes d’entre elles. Mais vers quelle URL ?
Il sera nécessaire de « faire matcher » ces URL abandonnées vers les pages les plus pertinentes et traitant de la même thématique, ou plutôt du même sujet. Il vous faudra pour cela passer par la qualification de vos contenus. Mais dans le cas où aucun élément présent dans l’URL ne vous permet d’avoir une vision précise du contenu de vos pages, et de la catégorie à laquelle elle appartient, vous devrez aller récupérer des éléments contenus dans la page pour vous permettre de la qualifier. Cela vous permettra par la suite d’identifier les produits non suivis d’une catégorie pour les rediriger plus facilement vers un produit similaire ou la page catégorie correspondantes.
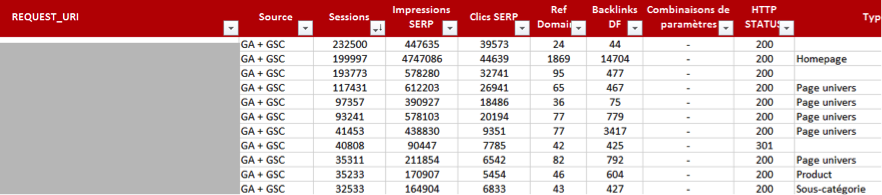
Fig. 1. Qualification des URL à migrer.
Supposons cette URL : /categorie/634/product-2984.html. Difficile de déterminer à partir de cette URL son contenu. Mais en récupérant des éléments dans la page comme le titre ou le fil d’ariane de la page, il sera aisé de classifier l’ensemble de ces URL.
![]() Aymeric Bouillat
Aymeric Bouillat
Consultant SEO Senior, Resoneo (http://twitter.com/aymerictwit et http://www.yapasdequoi.com)












![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-527x297.png)
![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-190x190.png)