

L’incendie survenu dernièrement dans les locaux de l’entreprise OVH à Strasbourg eut de nombreuses conséquences. Tandis que certains s’affairent à réaliser leurs déclarations de pertes de données auprès de la CNIL, d’autres réalisent aussi qu’Internet et le Cloud ne sont pas des entités magiques dans lesquelles toutes nos données sont à jamais conservées. Si l’adage reste « Internet n’oublie pas » pour conserver une vigilance constante sur ce que l’on publierait, dans un but de préservation de sa réputation, nous sommes bien forcés de constater que tout n’est pas si évident. Cet article propose un point de vue sur la gestion des contenus en ligne, et plus globalement de toute information qui pourrait être mise sur un réseau informatique. Au travers du prisme du SEO, nous verrons qu’une succession de décisions peut avoir un impact sur l’opinion et l’histoire.
Les archives d’aujourd’hui et de demain
Les outils de recherche en ligne sont nombreux. Google est certainement le premier, que ce soit pour rechercher une information, un produit à acheter ou sa prochaine destination de vacances. Selon Statista, 35 % des Français passent par un moteur de recherche pour trouver une information avec un enjeu d’actualité. Le référencement représente donc un enjeu non négligeable pour tous les éditeurs de site d’informations, quels qu’en soient les domaines d’expertise.
Si nous parlons d’archives en ligne, beaucoup se dirigeront vers le site web.archive.org et sa WayBack Machine qui permet littéralement de remonter le temps afin de consulter d’anciennes versions de sites Web. En France, la Bibliothèque nationale de France (BnF) collecte les données de certains sites en vue d’enrichir sa base dans le cadre du « dépôt légal de l’Internet ». Il est possible de faire une demande de dépôt légal, ou dans certains cas nous recevons, comme dans l’illustration ci-dessous, une notification directe de la part du service d’attribution de numéro ISSN.
La BnF ayant pour but de collecter les publications françaises depuis le XVIe siècle, elle a naturellement continué son travail dans le domaine du numérique. La simple existence de ce dépôt légal de l’Internet révèle les enjeux que peut avoir un contenu en ligne. Il peut être un descriptif de produit, un article pédagogique, un essai littéraire, un poème d’adolescent, et une part de patrimoine… sans que ces qualificatifs s’opposent.
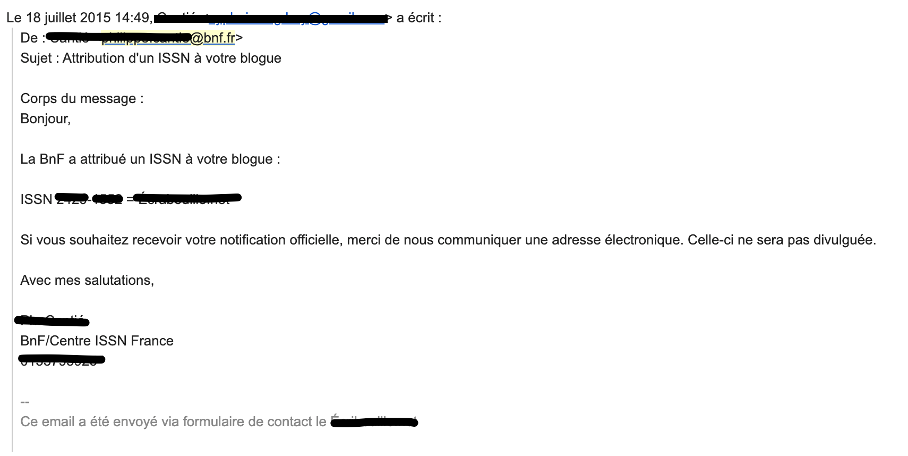
Fig. 1. Une notification d’attribution de numéro ISSN.
Les outils que sont les moteurs de recherche nous apportent un gain de temps précieux. Imaginez-vous une minute devoir retrouver une information dans la masse nébuleuse de sites Web sans un outil aussi puissant que Google et ses concurrents ?
Mais que faire de toutes ces pages ?
Quotidiennement les gestionnaires de site Web doivent faire face à une réflexion, pas si évidente, en ce qui concerne la gestion de leurs contenus. Plus le temps passe, plus la question de la sauvegarde ou de l’élagage se pose. Certaines pages ne servent à rien, c’est un fait, lorsqu’un produit n’est plus disponible, ou bien lorsque l’article est totalement obsolète. Pourtant, la seule suppression de ces contenus doit faire l’objet d’une réflexion. Plusieurs cas de figure se présentent alors.
Entasser sans compter : la technique du grenier qui déborde
Les sites d’actualités et les blogs souffrent du défaut de voir leurs contenus progressivement enterrés par les plus récents. Avec un affichage antéchronologique, plus on publie, plus les anciennes pages vont loin dans l’arborescence. Des Landing Pages thématiques et un maillage interne astucieux permettent presque de régler la chose. Cependant, cela n’est pas forcément un enjeu problématique puisque l’accumulation de pages et de contenus dans le temps est un mode de fonctionnement central pour ces types de sites Web. Le travail d’optimisation consiste plus à assurer que les pages les plus profondes demeurent accessibles, plutôt que de tenter de tout trier et ainsi de jeter des articles. Ces contenus, même s’ils semblent mineurs, pourraient très bien représenter une part importante de trafic lorsqu’on les cumule. C’est la raison pour laquelle il vaut mieux conserver une vision pragmatique avant de décider de simplement supprimer une rubrique. Et si l’on revient à l’idée des archives numériques, pouvoir continuer à consulter des publications antérieures est un usage qu’il ne faudrait pas trop mettre de côté. Le Courrier International met par exemple à disposition toutes ses archives de magazines depuis 1990 (Fig. 2), et un certain nombre d’articles qui y figurent.
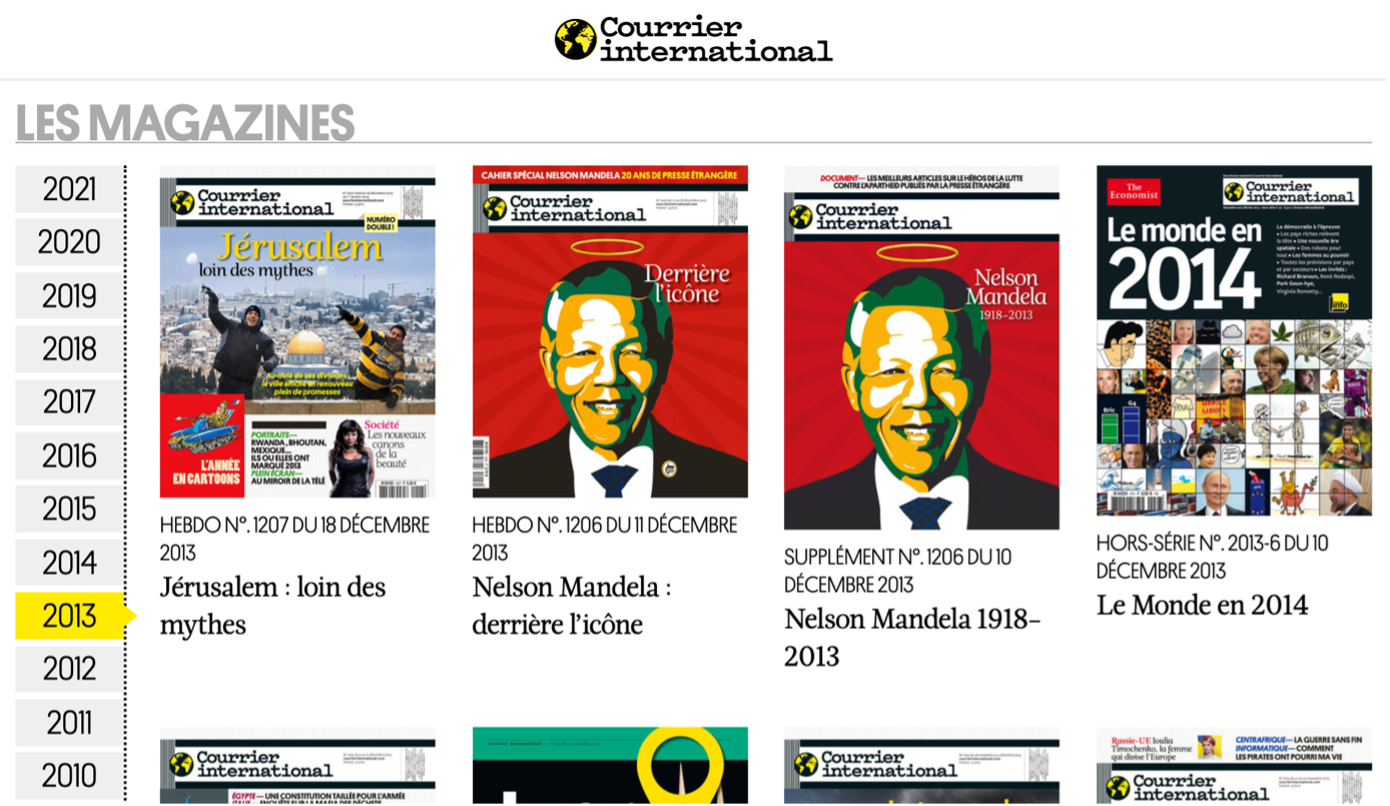
Fig. 2. Dans sa version numérique, le Courrier International propose de consulter l’historique des magazines pour accéder aux articles mis en ligne également.
En ce qui concerne les sites e-commerces, pourquoi devrions-nous garder en ligne des produits qui ne sont plus disponibles à la vente ? Quel en serait l’intérêt ? Puisque ces pages ne sont pas génératrices de chiffre d’affaires, dans une gestion où l’on recherche la rentabilité, peu d’arguments vont en faveur de la conservation des historiques publics de ses anciens catalogues.
L’item indisponible, le sera-t-il indéfiniment ? Est-ce un produit phare, qui même s’il n’est plus édité, mérite une mise en avant ? Les enseignes qui réalisent des collections issues de collaborations éphémères pour acquérir une notoriété plus large sont bien heureuses de conserver un historique de leurs actions. « Supprimer et rediriger » se révèle ne pas être systématiquement la manœuvre la plus intéressante. Aussi, lorsqu’un commerce en ligne souffre d’une incapacité à renouveler très fréquemment ses stocks, s’il ne conservait pas en ligne ses références vendues, il risquerait de présenter momentanément un catalogue vide.
C’est à ce moment-là que l’on peut se rendre compte que la stratégie de gestion des produits affichés sur un site de vente est une affaire de SEO mais aussi d’image de marque. Cela n’était-il pas déjà le cas ?
Trier c’est gagné, ce contenu m’apporte-il de la joie ?
Voici une citation de Marie Kondo, celle qui a écrit le best-seller La magie du rangement. Elle prône la méthode de « la joie » pour savoir si l’on doit garder ou non un objet au moment de trier ses affaires. Derrière ce concept, on retrouve l’idée qu’un objet (ou un contenu en ligne) a une fonction particulière. Même s’il semble inutile, il pourrait très bien avoir une autre valeur. C’est la raison pour laquelle on garderait par exemple en ligne des contenus a priori moins à la mode, mais qui continuent pourtant de générer un trafic non négligeable. C’est l’illustration même de la théorie de la longue traîne.
Les anglophones utilisent l’expression « content pruning » pour parler de la suppression de contenu après une phase de tri. La métaphore de l’élagage est assez efficace : trier, supprimer, pour mieux croître. Malheureusement, il faut parfois faire le même travail que lorsque l’on doit trier ses chaussettes favorites. Certaines pages ne servent concrètement à rien et ce sont autant de méandres dans lesquels le robot d’un moteur de recherche se perd.
Or nous savons que son temps est précieux et que la bonne optimisation d’un site Web passe également par une structure efficace.
Cependant, toute personne ayant essayé de supprimer des pages dans le but d’optimiser son référencement naturel sait que cela n’est pas si évident de les désindexer. Au mieux, cela prend un peu de temps, au pire, cela nous contraint à entamer une enquête approfondie. Il est bien fréquent que l’on retrouve même des pages, ou des versions de sites, dont on a oublié l’existence. Un vieux nom de domaine renouvelé automatiquement, ou une version de travail encore indexé sont des faits qui arrivent si vite. L’indexation de pages à la volée sans aucune raison peut même devenir un problème technique majeur. Ainsi, l’indexation des filtres lors de la mise en place d’une navigation à facettes sur un site entraîne des freins SEO, si les bons choix technologiques ne sont pas réalisés à temps.
Panorama de motivations pour la suppression de pages
Lorsque le cœur de l’éditeur de site Web balance, des arguments pragmatiques permettent de prendre des décisions.
| Absence de trafic | Dans votre outil d’analyse de trafic entrant, vérifiez les performances des pages. Veillez à ne pas regarder uniquement le trafic généré par le canal SEO afin d’obtenir une vision globale. Aussi, des pages qui génèrent peu de trafic peuvent être conservées lorsque cela est important pour l’image de marque. |
| Hits Googlebot | Une analyse de logs (le journal des activités sur les serveurs) vous permet de visualiser l’activité des robots de Google sur votre site. Ainsi, vous identifiez les pages qui consomment un budget de crawl très important sur des pages peu pertinentes. Avez-vous déjà regardé le temps que passait Googlebot sur vos pages de rubriques aux paginations interminables ? |
| Maillage interne | Des pages a priori pas si pertinentes se révèlent importantes pour le maillage interne d’un site Web. Le maillage interne est un outil habile pour permettre de lier des pages aux thématiques connexes entre elles ou pour inviter Googlebot à visiter des contenus placés profondément, de fait, dans l’arborescence. |
Fig. 3. Tableau de bord des hits Googlebot pour un site Web dans OnCrawl.
Cette vision macro est à prendre avec des pincettes car une analyse sur une période trop courte
risque de ne pas être représentative lorsqu’un site est soumis à de forts effets de saisonnalité.
Quand vous supprimez une page, vérifiez également votre maillage interne pour éviter que le robot ne tombe inutilement sur des erreurs 404. Cela risque d’être contre-productif, surtout si vous avez justement choisi de faire du tri afin d’optimiser votre structure pour le référencement naturel. Un crawler (Fig. 4) facilite grandement la tâche pour retrouver les pages depuis lesquelles est maillée un contenu supprimé.
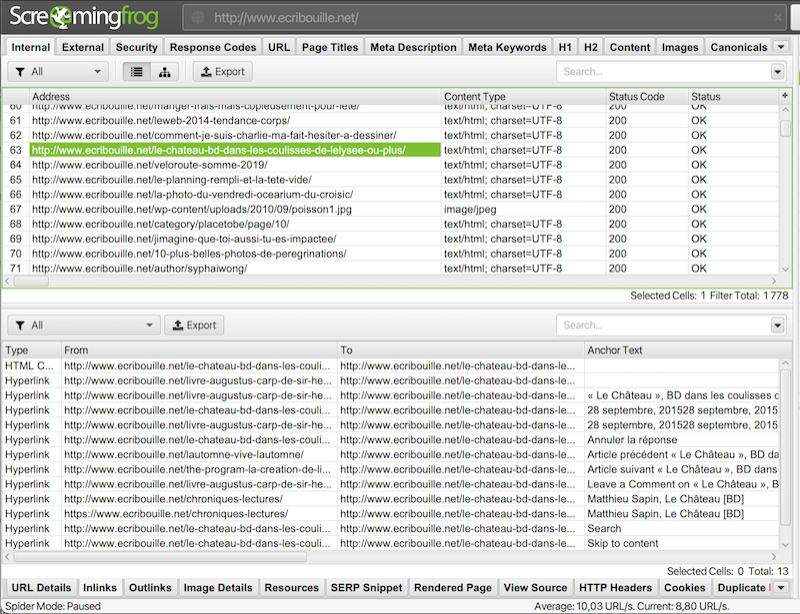
Fig. 4. Consultation des sources de liens internes pour une URL dans le crawler Screaming Frog.
Une page supprimée reste indexée dans Google
Vous avez supprimé une page mais elle est toujours indexée, sans que vous ne compreniez pourquoi ? Ces facteurs, ou leurs combinaisons, tendent à ralentir la désindexation.
| Lien externe | La page répond en 404 mais elle est maillée depuis un site externe. Ce n’est pas nécessairement affolant, il faut simplement s’armer de patience. Pour supprimer une page, on considère le code réponse 410 (« Gone ») plus efficace. Astuce : Rediriger en 301 cette URL vers une URL valide permet de récupérer ce backlink pour le référencement, mais aussi pour envoyer l’utilisateur vers un contenu plus pertinent qu’un « Not Found ». |
| Sitemap.xml | Votre fichier sitemap.xml est-il à jour ? |
| Soft 404 | Vérifiez que la page supprimée ne répond pas avec un code 200. Dans ce cas, Google comprendra que la page est toujours active. Une configuration serveur devrait régler le problème. |
À noter que Google Search Console fournit également un outil de suppression de son index comme vous pouvez le voir sur Fig. 5
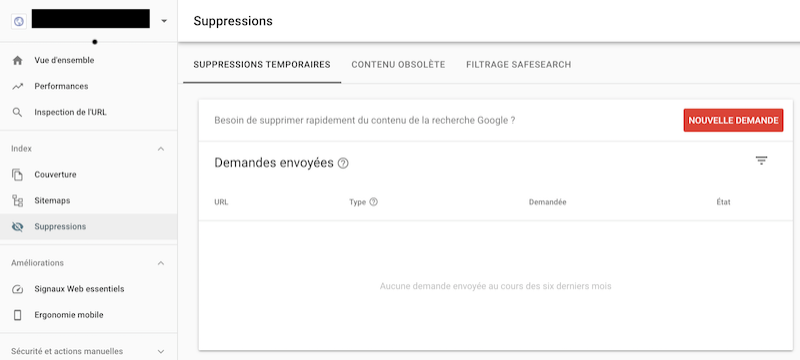
Fig. 5 Outil de demande de suppression dans l’index Google via Google Search Console.
Identité numérique : le droit à l’oubli dans la pratique
Les professionnels de la réputation en ligne connaissent bien le sujet. Lorsqu’une information qui ne nous arrange pas circule, on peut demander un « déréférencement » pour «la suppression de résultats de recherche Google spécifiques incluant votre nom ». Le formulaire est simple à remplir, il suffit ensuite d’attendre que le contenu litigieux ne soit plus indexé. Contrairement à ce que l’on pourrait faire croire, le contenu demeure bien en ligne. Le fait de désindexer ne fait que réduire les voies d’entrée vers les informations que l’on ne souhaite pas voir diffuser.
La mise en place du dispositif n’est pas si simple. Il ne suffit pas de demander une désindexation pour l’obtenir immédiatement et irrémédiablement. Les contenus que certains considèrent comme étant frauduleux ne le sont pas forcément pour d’autres. Ainsi, des informations publiques ou qui concernent des personnalités publiques ne peuvent pas faire l’objet d’un droit à l’oubli si facile.
À défaut de pouvoir supprimer de l’index d’un moteur de recherche un contenu, l’autre technique consiste à la dissimuler. Il s’agit d’une technique que l’on pourrait résumer par l’expression « noyer le poisson ». En théorie, il faut publier soi-même des contenus à son propre sujet afin de modeler son identité numérique. Progressivement, les informations qui nous désavantagent sont renvoyés dans les deuxième, troisième… pages de Google, s’ils ne tombent pas simplement dans l’oubli.
En usant du formulaire pour la désindexation, ou en noyant le poisson, il est souvent utile de rappeler que les contenus ne sont pas supprimés pour autant. Même s’ils sont moins facilement accessibles, en comptant surtout sur le manque d’attrait des utilisateurs pour la spéléologie numérique, ces contenus demeurent disponibles pourvu que l’on trouve le chemin d’accès.
Kim Dotcom et Donald Trump, des anecdotes pas si anodines
Voici deux exemples où des personnes ont subi malgré elles la suppression de leurs contenus.
L’aventure de Kim Dotcom
En raison du non-respect de la loi DMCA (« Digital Millennium Copyright Act »), le propriétaire du site de téléchargement illégal MegaUpload reçut la visite d’agents du FBI en 2012 pour la fermeture du site par une simple saisie des données. Les autorités américaines sont donc intervenues physiquement afin de faire cesser les activités de MegaUpload, et de son propriétaire Kim Dotcom. Contrefaçons, blanchiment d’argent… les chefs d’accusation font encourir à Dotcom et 6 autres personnes une peine pouvant aller jusqu’à 60 ans de prison. Pourtant, MegaUpload avait auparavant été prévenu, mais « L’entreprise ne supprimait que le lien envoyé par l’ayant droit, et non le contenu correspondant, qui pouvait être retrouvé sous d’autres liens » comme le rapporte Numerama dans son article daté du 20 janvier 2012.
Les contenus frauduleux étaient donc toujours en ligne, quelque part, accessibles. Ils ont faussement été supprimés en n’enlevant qu’un des nombreux chemins d’accès qui permettaient de les consulter. De la même façon que l’on pourrait avoir des contenus en ligne, mais qui ne sont pas indexés dans Google.
Quand Donald Trump quitta Twitter
En janvier 2017, la passation de pouvoir entre Barack Obama et Donald Trump a permis à ce dernier de récupérer le compte Twitter @Potus pour « President of the United States ». La passation des comptes n’est pas si anodine, car tout ce qui est publié via les comptes @Potus et @Flotus (« First Lady of the United States ») permet aussi d’archiver les déclarations de ces personnalités politiques.
C’est ainsi que nous pouvons aujourd’hui encore lire les tweets d’Obama sur la Fig. 6 en tant que Président sur le compte @Potus44.
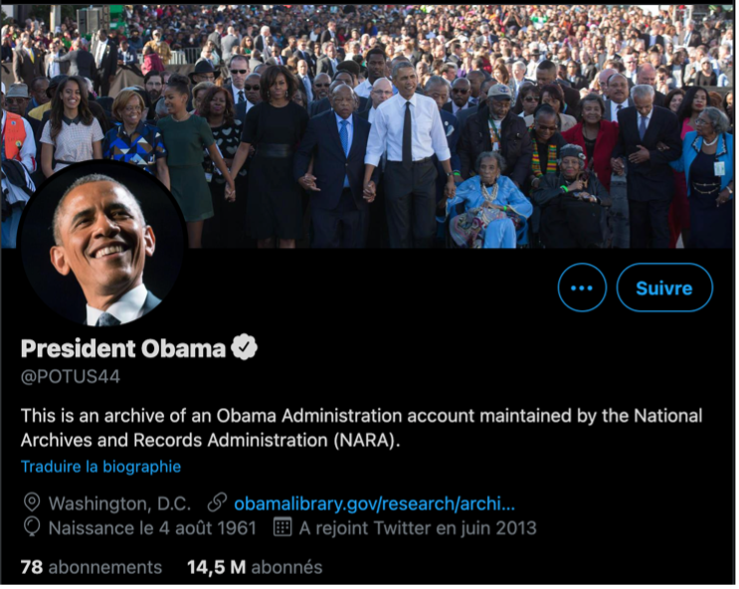
Fig. 6. Le compte @Potus44, l’archive des tweets de Barack Obama en tant que Président des États-Unis.
La suspension des tweets du compte personnel de Donald Trump (@realDonaldTrump) en janvier 2021 pose aussi la question des archives des déclarations de l’ancien Président. En effet, Trump a rapidement pris le parti de tweeter majoritairement depuis son compte personnel plutôt que @Potus, aujourd’hui @Potus45. Les déclarations de l’homme d’affaires, et politiques, ne sont donc plus disponibles. Sans discuter les raisons pour lesquelles le compte est suspendu, la non-disponibilité de ces tweets pourrait également communiquer une histoire partielle. Les tweets apparaissant lors de la recherche dans Google liée à un nom propre (Fig. 7), la gestion de son compte Twitter a une influence sur la réputation numérique d’une personne de façon globale.
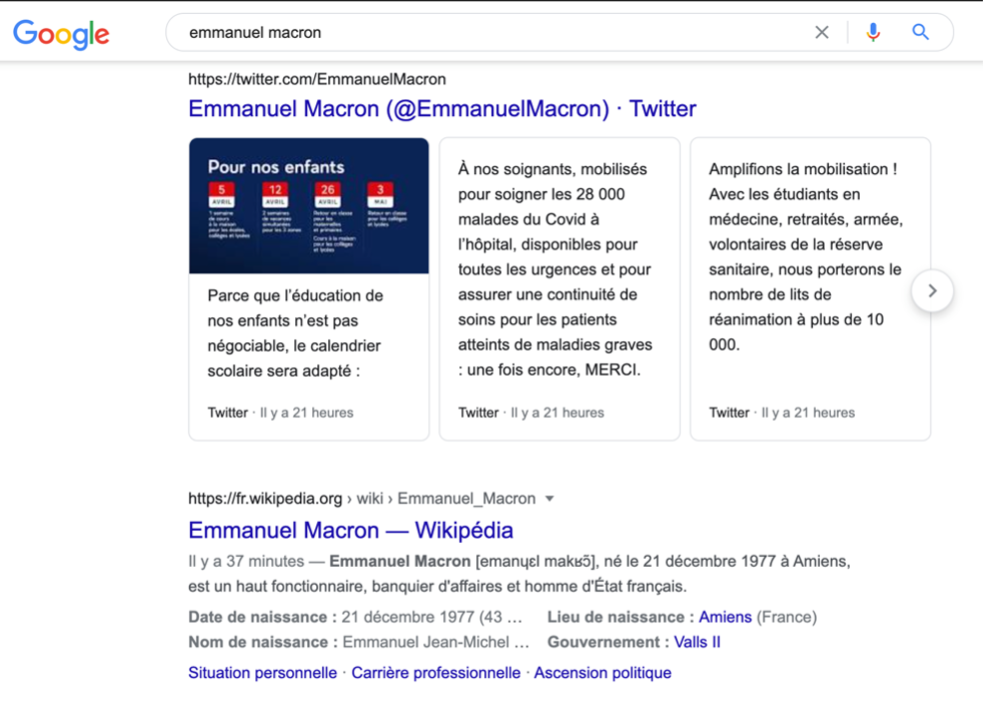
Fig. 7. Indexation et visibilité d’un compte Twitter pour une personnalité politique.
Nos contenus d’aujourd’hui sont les archives de demain
Lorsque la bataille pour la visibilité consiste à être le plus haut possible dans les résultats des moteurs de recherche, l’indexation est déjà une première étape. La BnF fait son travail de collecte de publications numériques pour constituer des archives et des collections. Pour autant, ce qui n’est pas validé par une demande de dépôt légal auprès de l’institution n’est pour autant pas à jeter. À titre de comparaison, nous retrouvons aujourd’hui des archives de publicités anciennes, et de catalogues de vente sur des sites comme Gallica, Wikimedia Commons, ou Flickr Commons. Les historiques de nos sites Web e-commerce pourraient eux aussi devenir les contenus vintages d’utilisateurs du futur. Il serait même intéressant pour le lecteur d’aujourd’hui de constater dans 30 ans ce qu’il restera de nos publications de 2021.













![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-527x297.png)
![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-190x190.png)
5