
 Toute personne qui s’intéresse de près ou de loin au SEO (et pas seulement) a certainement, un jour ou l’autre, utilisé la Wayback Machine ou Archive.org, qui sauvegarde des milliards de pages web depuis plus de 25 ans. Mais connaissez-vous toutes les fonctionnalités de cet outil et les différentes façons de s’en servir ? Voici un guide des différents trucs et astuces pour garder la mémoire alerte…
Toute personne qui s’intéresse de près ou de loin au SEO (et pas seulement) a certainement, un jour ou l’autre, utilisé la Wayback Machine ou Archive.org, qui sauvegarde des milliards de pages web depuis plus de 25 ans. Mais connaissez-vous toutes les fonctionnalités de cet outil et les différentes façons de s’en servir ? Voici un guide des différents trucs et astuces pour garder la mémoire alerte…
 Toute personne qui s’intéresse de près ou de loin au SEO (et pas seulement) a certainement, un jour ou l’autre, utilisé la Wayback Machine ou Archive.org, qui sauvegarde des milliards de pages web depuis plus de 25 ans. Mais connaissez-vous toutes les fonctionnalités de cet outil et les différentes façons de s’en servir ? Voici un guide des différents trucs et astuces pour garder la mémoire alerte…
Toute personne qui s’intéresse de près ou de loin au SEO (et pas seulement) a certainement, un jour ou l’autre, utilisé la Wayback Machine ou Archive.org, qui sauvegarde des milliards de pages web depuis plus de 25 ans. Mais connaissez-vous toutes les fonctionnalités de cet outil et les différentes façons de s’en servir ? Voici un guide des différents trucs et astuces pour garder la mémoire alerte…La WayBack machine est un excellent outil pour retrouver des contenus perdus ou d’anciennes versions de ces derniers. On peut aussi facilement l’utiliser dans une optique de veille concurrentielle ou de monitoring. Mais comment et quand l’utiliser dans nos actions de référencement naturel ? Voici un guide des différents atouts de cet outil Open Source.
Qu’est-ce que la WayBack Machine ?
La WayBack Machine est un organisme à but non lucratif ayant pour objectif de constituer la plus grande archive mondiale des contenus du Web. Depuis 1996, ils sauvegardent des millions de contenus textes, mais aussi des livres, des vidéos ou encore des fichiers audio.
Ainsi, à n’importe quel moment, vous pouvez demander à l’outil de vous donner les différentes sauvegardes d’une URL précise. Vous aurez alors un historique de différentes versions disponibles, le tout accessible avec un simple clic sur la partie calendrier.
Dans l’exemple ci-dessous, on demande ainsi les différentes sauvegardes de la page d’accueil du site SeoMix.fr. On voit alors la première sauvegarde fin 2009, et l’on ensuite accès à 660 versions du contenu concerné.
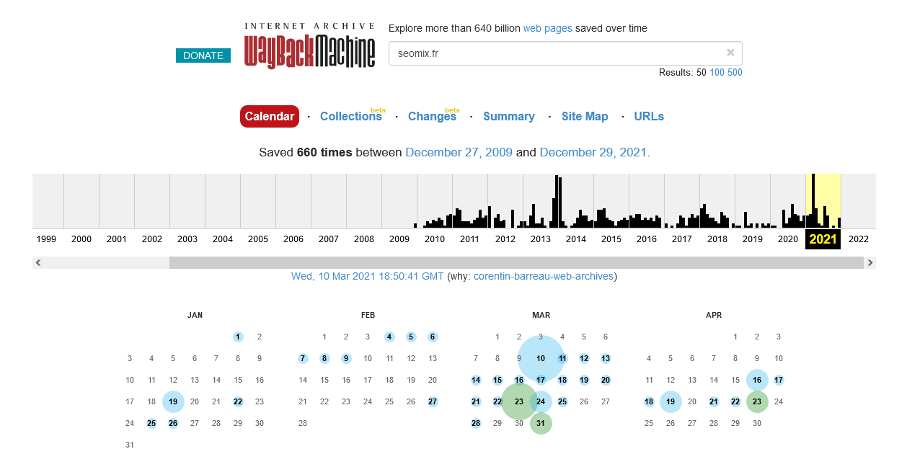
Un exemple des sauvegardes disponibles pour la page d’accueil de SeoMix.fr
Lorsque vous cliquez sur l’un des liens dans le calendrier, vous afficherez alors la sauvegarde du contenu concerné :

Un exemple de sauvegarde au 01 Janvier 2021
















5
4.5
5