
 Parmi les codes réponses qui peuvent être renvoyés dans les en-têtes HTTP par un serveur aux navigateurs ou aux crawlers sur la demande d’une URL, les statuts HTTP 200 sont en général les plus représentés (200 : Requête traitée avec succès). D’autres codes réponses peuvent être renvoyés comme les erreurs 404 (ressource non trouvée) ou 410 (la ressource n’est plus disponible), ainsi que des redirections 301 ou 302 en cas de déplacement d’une URL. Mais un code réponse particulier (et assez peu connu et utilisé) peut être renvoyé dans certains cas par les serveurs. Il s’agit du statut HTTP 304, qui signifie que le document n’a pas été modifié depuis la dernière requête. Nous allons aborder dans cet article son fonctionnement, ainsi que son intérêt d’un point de vue utilisateur, mais également des enjeux que ce code réponse peut avoir d’un point de vue SEO.
Parmi les codes réponses qui peuvent être renvoyés dans les en-têtes HTTP par un serveur aux navigateurs ou aux crawlers sur la demande d’une URL, les statuts HTTP 200 sont en général les plus représentés (200 : Requête traitée avec succès). D’autres codes réponses peuvent être renvoyés comme les erreurs 404 (ressource non trouvée) ou 410 (la ressource n’est plus disponible), ainsi que des redirections 301 ou 302 en cas de déplacement d’une URL. Mais un code réponse particulier (et assez peu connu et utilisé) peut être renvoyé dans certains cas par les serveurs. Il s’agit du statut HTTP 304, qui signifie que le document n’a pas été modifié depuis la dernière requête. Nous allons aborder dans cet article son fonctionnement, ainsi que son intérêt d’un point de vue utilisateur, mais également des enjeux que ce code réponse peut avoir d’un point de vue SEO.
 Parmi les codes réponses qui peuvent être renvoyés dans les en-têtes HTTP par un serveur aux navigateurs ou aux crawlers sur la demande d’une URL, les statuts HTTP 200 sont en général les plus représentés (200 : Requête traitée avec succès). D’autres codes réponses peuvent être renvoyés comme les erreurs 404 (ressource non trouvée) ou 410 (la ressource n’est plus disponible), ainsi que des redirections 301 ou 302 en cas de déplacement d’une URL. Mais un code réponse particulier (et assez peu connu et utilisé) peut être renvoyé dans certains cas par les serveurs. Il s’agit du statut HTTP 304, qui signifie que le document n’a pas été modifié depuis la dernière requête. Nous allons aborder dans cet article son fonctionnement, ainsi que son intérêt d’un point de vue utilisateur, mais également des enjeux que ce code réponse peut avoir d’un point de vue SEO.
Parmi les codes réponses qui peuvent être renvoyés dans les en-têtes HTTP par un serveur aux navigateurs ou aux crawlers sur la demande d’une URL, les statuts HTTP 200 sont en général les plus représentés (200 : Requête traitée avec succès). D’autres codes réponses peuvent être renvoyés comme les erreurs 404 (ressource non trouvée) ou 410 (la ressource n’est plus disponible), ainsi que des redirections 301 ou 302 en cas de déplacement d’une URL. Mais un code réponse particulier (et assez peu connu et utilisé) peut être renvoyé dans certains cas par les serveurs. Il s’agit du statut HTTP 304, qui signifie que le document n’a pas été modifié depuis la dernière requête. Nous allons aborder dans cet article son fonctionnement, ainsi que son intérêt d’un point de vue utilisateur, mais également des enjeux que ce code réponse peut avoir d’un point de vue SEO.Visualiser le code réponse « 304 Not Modified »
Pour afficher les différents codes réponses pour chaque élément chargé lors de l’affichage d’une page Web, il est possible de passer par l’onglet « Réseau » ou « Network » de l’inspecteur d’éléments des principaux navigateurs Web :
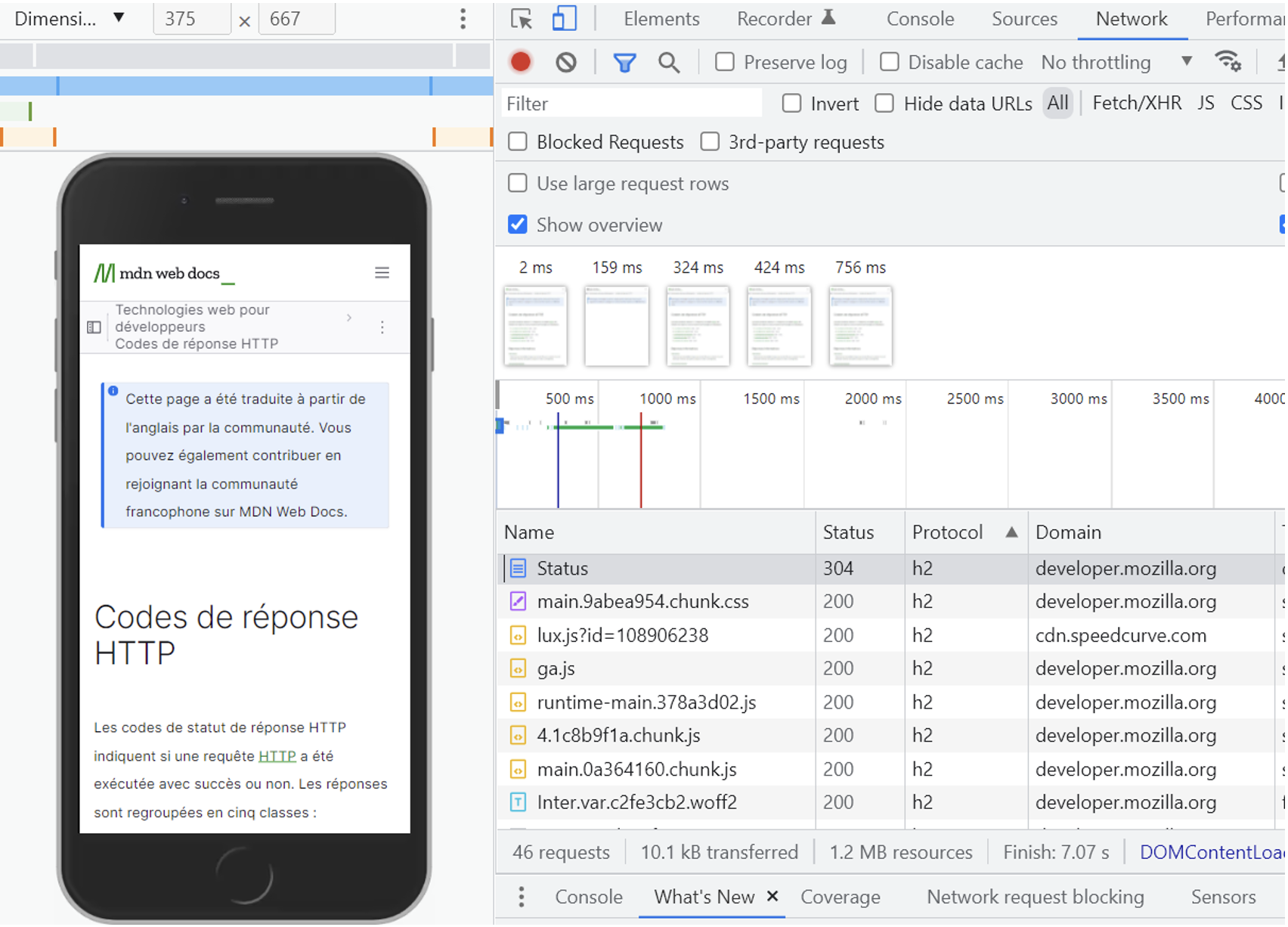
Codes réponses reçus par le navigateur pour chaque élément d’une page
Le code de réponse 304 Not Modified indique au serveur qu’il n’est pas nécessaire de retransmettre les ressources demandées. C’est une redirection implicite vers une ressource mise en cache au préalable. Mais comment le serveur peut-il décider de ne pas renvoyer une ressource car cette dernière serait déjà en cache ?














![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-527x297.png)
![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-190x190.png)
5