
On entend de plus en plus parler de la prise en compte par les moteurs de recherche de critères mesurant la satisfaction de l’utilisateur pour les résultats renvoyés par l’algorithme de pertinence. Des systèmes comme le learning-to-rank ou le re-ranking apparaissent en effet et montrent bien à quel point notre vision du SEO se doit d’évoluer pour prendre en compte cette nouvelle donne.
Depuis quelques années, les moteurs de recherche emploient un signal de qualité utilisateur pour travailler les classements qui sont proposés aux utilisateurs.
Pour cela, plusieurs algorithmes ont été mis au point : des filtres de qualité (comme le fameux Panda), des algorithmes de re-ranking (qui modifient le classement selon une extrapolation de la qualité perçue par l’analyse du comportement de l’utilisateur vis-à-vis de la SERP) ou encore l’algorithme de learning-to-rank.
Dans cet article, nous allons voir comment un moteur peut extrapoler ce que va penser un internaute de la qualité de la SERP, puis nous verrons rapidement la notion de re-ranking et celle de learning-to-rank, et enfin nous parlerons SEO.
Mesurer la satisfaction d’un utilisateur : pas si facile pour le moteur
La première tâche à faire pour utiliser un signal de satisfaction utilisateur est bien entendu de qualifier celle-ci. Il existe de très nombreuses méthodes (voir les articles [1], [2] et [3] par exemple), mais nous allons en évoquer trois :
-
- L’approche active : combiner deux SERP.
L’approche, présentée pour la première fois par une équipe de Bing (référence [1]), consiste à produire deux SERP différentes pour un même résultat, et à entrelacer les résultats de ces deux SERP en mettant côte à côte le premier résultat de chaque SERP, puis le deuxième, etc. (sauf quand il s’agit du même résultat ou d’un résultat déjà proposé plus haut par une des deux SERP).
Si on le fait avec suffisamment d’utilisateurs (ce qui nécessite un volume de recherche conséquent), dans une logique d’A/B testing, alors on peut très rapidement savoir quelles sont les URL préférées par les utilisateurs pour chaque requête. - Utiliser le taux de clic, mais intelligemment .
Le critère du taux de clic consiste à compter le nombre de clics sur chaque résultat pour déterminer la valeur de l’URL correspondante. Il s’agit d’un critère difficile à appréhender pour le moteur, car il est sujet à de nombreux biais liés au moteur lui même. En effet, la position d’un résultat à une influence sur le taux de clic, indépendamment de sa qualité. On trouve par exemple dans l’article [2] le graphique de la figure 1 (il s’agit de l’évaluation d’un moteur de recherche d’articles).
- L’approche active : combiner deux SERP.
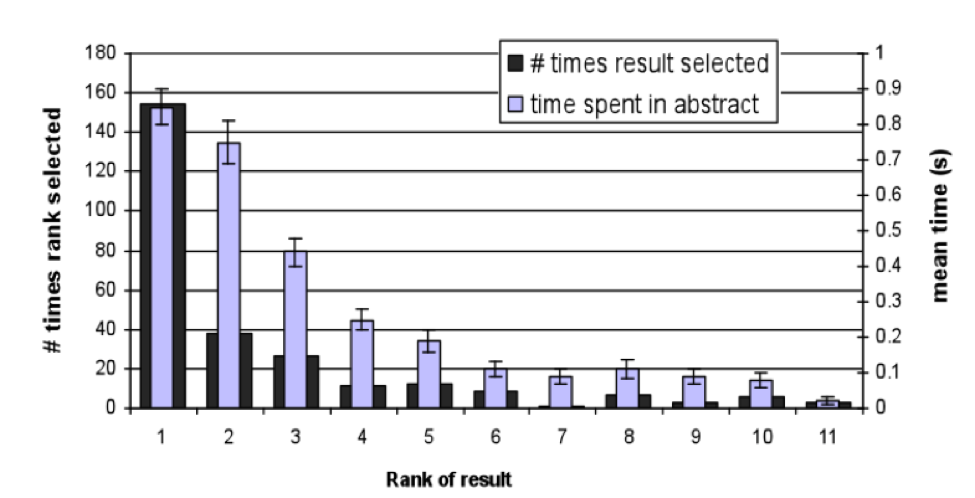
Fig. 1. Nombre de clics par position.
On voit bien avec cette figure que prendre en compte uniquement le nombre de clics ne convient pas pour déterminer la qualité perçue par un utilisateur : il va falloir mettre le nombre de clics au regard de la position pour comprendre réellement l’avis de l’utilisateur.
Pour cela, on va calculer la déviation au taux de clic moyen.
Si on connaît les taux de clic moyen par position, on pourra, en regardant le taux de clic d’une URL spécifique à une position donnée, savoir si cette URL est en moyenne plus ou moins qualitative que ce que l’on attend.
Par exemple, si on sait que le résultat en première position est cliqué en moyenne 15% du temps tandis que celui en deuxième position l’est 10% du temps, et que la page toto.com est en première position pour la requête blague avec un taux de clic de 5% alors que la page blague.com est deuxième avec un taux de clic de 20%, alors on peut rapidement conclure que la page blague.com est plus pertinente que la page toto.com pour cette requête.
- Utiliser le clic-skip.
Une partie du temps, l’utilisateur d’un moteur veut réellement trouver une information et il va donc parcourir plusieurs pages jusqu’à ce qu’il trouve ce qu’il cherche.
Le moteur peut, en analysant le parcours de la personne en question, comprendre quelle est la page qui répond le mieux à la requête exprimée.
Par exemple, imaginons que sur la requête blague, un internaute voit le site toto.com, puis revienne sur le moteur et regarde blague.com et ne revient jamais. Imaginons qu’un deuxième internaute fasse la même demande et regarde blague.com et ne revienne plus, etc. Au bout d’un moment on a un pattern très clair : la page blague.com semble mieux remplir sa mission informationnelle puisque la plupart des visiteurs finissent par la visiter, et c’est la plupart du temps le point de sortie de la recherche.
Une fois que l’on a une métrique permettant de bien qualifier ce que les utilisateurs préfèrent, que va t-on faire avec celle-ci ? Elle va typiquement nourrir des algorithmes qui auront pour but d’améliorer les SERP proposées par le moteur.
Le learning-to-rank : une pondération des signaux différente pour chaque requête
Vous le savez déjà : de très nombreux signaux sont utilisés par le moteur. Certains sont des signaux absolus (le PageRank,le spam score,etc.) tandis que d’autres sont des signaux relatifs (taux de duplication, EMD, date de première apparition dans l’index, etc.). Enfin, certains signaux sont relatifs à la requête en elle-même (par exemple le cosinus de salton pour déterminer la pertinence sémantique).
Pour le moteur, une question est cruciale : comment faire pour donner un unique classement aux pages alors qu’il existe autant de signaux ?
Pour répondre à cette question, le moteur va agréger les scores de chacun des signaux pour obtenir une valeur unique pour chaque page. C’est un sujet que nous avons déjà abordé il y a un an dans cette lettre, mais pour résumer, le moteur va faire une somme pondérée des différents signaux pour créer un signal unique de classement. La question restante est donc : comment calculer ces pondérations ?
C’est là où l’algorithme de learning-to-rank rentre en jeu (voir la référence [4] pour avoir les détails techniques). La figure 2 va nous servir de support à la compréhension.
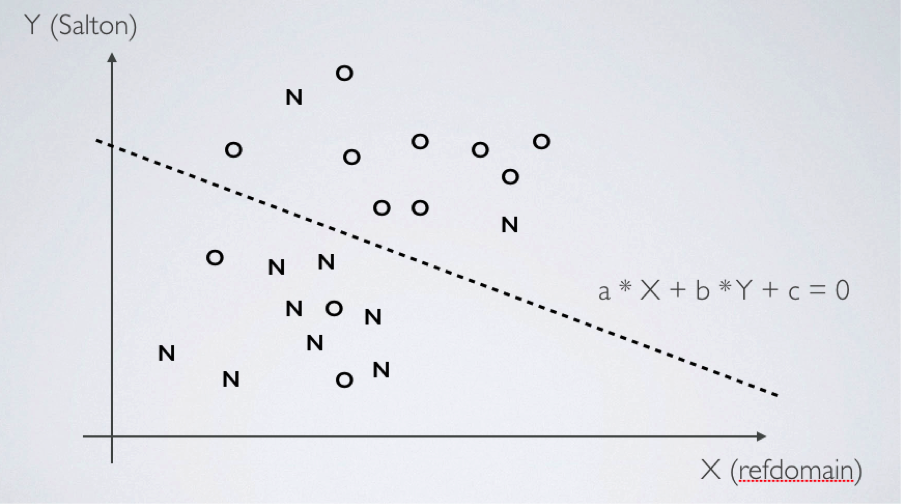
Fig. 2. Système de learning-to-rank.
Sur cette figure, chaque “O” et “N” correspond à une URL qui a été notée comme pertinente (O) ou non (N) par un algorithme d’évaluation de la qualité perçue. Chacune de ces URL est placée sur la plan selon la valeur de son signal “cosinus de salton” et de son signal “nombre de domaines référents”.
On voit que les résultats pertinents sont (grosso modo) regroupés, et qu’il en va de même pour les non pertinents. L’algorithme de learning-to-rank va apprendre les paramètres de la droite qui sépare les deux groupes, ce qui permet de trouver les pondérations de signaux qui vont donner un score adapté (haut pour ce qui est au-dessus de la droite, bas pour ce qui est en dessous).
Re-ranking : si tu me plais, tu passes devant
La notion clé du re-ranking est celle de la rétropropagation implicite de pertinence : regarder en temps réel la métrique de qualité perçue pour prendre des décisions de modification du classement en temps réel.
La principale difficulté de l’approche est la mise en place d’un système de monitoring permanent transparent en termes de performances (il ne faut pas allonger le temps de réponse) alors que par exemple le learning-to-rank n’a pas forcément besoin d’être temps réel (même si c’est le cas pour les plus grands moteurs).
Mis à part cela, le principe est simple : si par exemple on pense que la page en position 3 est plus méritante que la page 2, on inverse tout simplement les deux.
Mesurer la satisfaction d’un utilisateur : encore plus dur pour le SEO
Vous l’avez compris, le moteur a besoin de comprendre la qualité vue par l’oeil de ses utilisateurs. Cette mesure de la qualité perçue est faite indirectement, par des métriques liées aux clics, au temps de retour et parfois au temps passé sur les pages, etc. Quand on est SEO, on a donc deux tâches à effectuer, qui sont en fait 3 tâches :
- Comprendre comment les utilisateurs perçoivent la qualité de vos pages web.
- Modifier tout cela pour :
- Rendre réellement les pages de meilleure qualité pour vos visiteurs.
- Faire croire au moteur que vous avez amélioré la qualité (bouh ! c’est mal).
Commençons par aborder la première tâche. Mesurer ce que pensent vos utilisateurs venus des moteurs est très compliqué. Dans la littérature du folklore SEO, on vous dit de regarder le taux de rebond, ou le temps de lecture de la page, ou d’autres métriques de ce type. Mais aucune d’entre elles n’a de sens prise séparément. C’est un mélange de métriques qui va vous donner des indications.
A titre personnel, nous classons les pages d’un site par le produit du temps passé * taux de rebond * taux de sortie. Ce n’est pas une métrique absolue et ce n’est pas non plus idéal, mais elle a le mérite de favoriser les pages qui sont longuement lues et qui ensuite ne créent pas de recherche supplémentaire d’information sur le site. A vous de vous construire votre propre mélange, ou de vous inspirer des recettes des confrères (voir notamment l’article [5] du site Webrankinfo).
Les “bonnes” pratiques
La seule vraie bonne pratique est bien entendu d’améliorer drastiquement la qualité des pages qui sont faibles. Pour cela il faut améliorer le contenu de chaque page (à l’aide d’un outil d’analyse sémantique, ce sera encore plus simple) et quand ce n’est pas possible arbitrer entre désindexation (cas de pages qui servent encore à quelque chose pour quelques rares utilisateurs) et suppression (page qui ne servent littéralement à rien).
Dans le cas de certaines pages type pagination, une réflexion sur leur nécessité ou sur l’éventualité de mettre un contenu dessus (automatiquement) doit se poser.
Si votre chapeau est plus sombre, vous pouvez également envisager de faire croire au moteur à une meilleure qualité. Pour cela, deux possibilités :
- Améliorer l’attractivité de la page au sein de la SERP (en bref : faire cliquer). Pour cela il faut des CTA (Call To Action) bien conçus au sein de la meta description, pour générer des snippet les plus attractifs possibles.
Dans ce cadre, vous êtes dans une logique de copywriting, que vous pouvez évaluer en A/B testant vos idées à l’aide de Google Adwords : une pub qui performe bien c’est souvent une description plus attractive en matière de SEO. - Améliorer la rétention : c’est-à-dire faire en sorte que les visiteurs restent un peu plus longtemps sur chaque page. Pour cela il existe de nombreuses astuces : mettre des vidéos (le temps de les lancer c’est déjà 1 ou 2 secondes en plus de temps de visite), faire des CTA à cheval sur la ligne de flottaison pour obliger les internautes à scroller mécaniquement vers le bas, etc.
Conclusion
Tous ces signaux sont utilisés depuis déjà plusieurs années par les moteurs (le learning-to-rank – le plus récent de tous – a été mis en place en 2014 chez Bing sous le nom de ranknet par exemple). Mais on se rend de plus en plus compte que les SEOs n’en avaient pas pris la mesure jusqu’ici, alors qu’il s’agit très clairement de leviers très puissants.
Le lecteur intéressé par en savoir plus du point de vue SEO pourra lire avec intérêt la référence [6] qui aborde concrètement un certain nombres de points connexes.
Références
[1] Radlinski, Filip, and Nick Craswell. “Optimized interleaving for online retrieval evaluation.” Proceedings of the sixth ACM international conference on Web search and data mining. ACM, 2013.
https://www.microsoft.com/en-us/research/content/uploads/2013/02/Radlinski_Optimized_WSDM2013.pdf.pdf
[2] Joachims, Thorsten, et al. “Evaluating the accuracy of implicit feedback from clicks and query reformulations in web search.” ACM Transactions on Information Systems (TOIS) 25.2 (2007): 7.
http://www.cs.cornell.edu/people/tJ/publications/joachims_etal_07a.pdf
[3] Agichtein, Eugene, Eric Brill, and Susan Dumais. “Improving web search ranking by incorporating user behavior information.” Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2006.
http://susandumais.com/sigir2006-fp345-ranking-agichtein.pdf
[4] http://wwwconference.org/www2009/pdf/T7A-LEARNING%20TO%20RANK%20TUTORIAL.pdf
[5] https://www.webrankinfo.com/dossiers/conseils/seo-satisfaction-utilisateur
[6] https://www.webrankinfo.com/dossiers/conseils/principaux-problemes-seo
![]() Sylvain Peyronnet, fondateur de la régie publicitaire sans tracking The Machine In The Middle (http://themachineinthemiddle.fr/).
Sylvain Peyronnet, fondateur de la régie publicitaire sans tracking The Machine In The Middle (http://themachineinthemiddle.fr/).
















5