

La recherche sur le Web ne se limite pas toujours à l’exploration des fichiers au formats HTML. D’autres possibilités (PDF, Word, Excel, Powerpoint, etc.) existent et les moteurs classiques les indexent et proposent même des syntaxes d’interrogation spécifiques. Mais bien d’autres moteurs verticaux sont disponibles et permettent parfois une exploration plus approfondie du Web pour les identifier. Cet article a pour but de les lister et de les comparer, car on trouve de tout à ce niveau aujourd’hui…
 Par Christophe Deschamps
Par Christophe DeschampsLes documents bureautiques sont présents en masse sur le Web et les moteurs de recherche généralistes comme Google et Bing y donnent un bon accès. Il existe cependant de nombreuses possibilités que nous ne pensons pas toujours à exploiter lorsque la recherche initiale n’a pas donné les résultats attendus.
Nous ne nous intéresserons cependant pas ici aux outils orientés spécifiquement sur la recherche d’informations scientifiques et techniques ou encore à ceux permettant de rechercher des documents issus de « leaks ».
Les moteurs généralistes et les métamoteurs
Afin de pouvoir comparer les résultats des différents types de services proposés ici, nous utiliserons pour chacun la requête « competitive intelligence ».
Google (https://www.google.com/)
Google est le premier moteur, à notre connaissance, à avoir proposé un opérateur permettant d’obtenir des documents bureautiques. Il s’agit bien sûr de « filetype: » auquel on accole l’extension du type de fichier que l’on souhaite obtenir.
Par exemple : “competitive intelligence” filetype:pdf
On pourra ainsi rechercher également des fichiers :
- Word : doc ou docx (attention la requête « doc » ne remonte pas de « docx », il faut donc faire deux requêtes pour être complet et il en va de même pour les autres formats propres à Windows : xls/xlsx, ppt/pptx, etc.). Cependant, vous pouvez utiliser l’opérateur OR comme ici : “competitive intelligence” filetype:doc OR filetype:docx.
Google trouve ici 405 000 résultats mais seuls 170 sont annoncés comme disponibles. Frustrant…
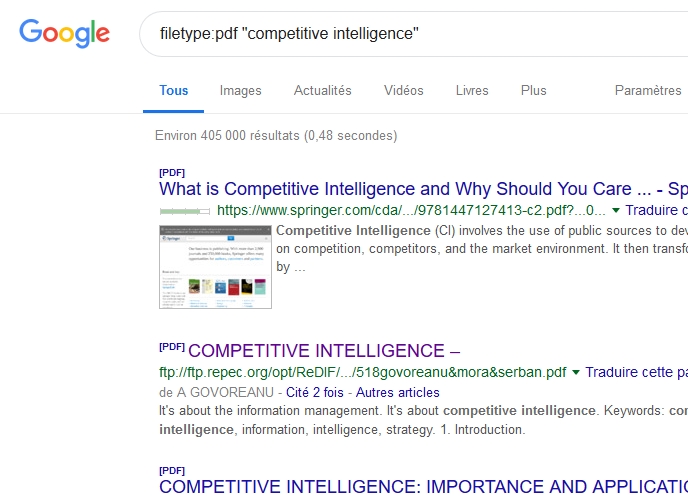
Fig.1. Résultats d’une recherche de fichiers dans Google.
Bing (https://www.bing.com)
Bing utilise le même opérateur que Google (filetype:) pour permettre la recherche de fichiers. Sur la même requête, il n’affiche « que » 384 000 résultats mais permet semble t-il d’accéder à tous.
![]() Christophe Deschamps, Consultant-formateur : veille stratégique, intelligence économique, social KM, e-réputation, mindmapping, IST (http://www.outilsfroids.net/)
Christophe Deschamps, Consultant-formateur : veille stratégique, intelligence économique, social KM, e-réputation, mindmapping, IST (http://www.outilsfroids.net/)
















5