

Google, tout comme les autres moteurs de recherche, essaie de visualiser le rendu réel de vos pages comme le feraient les utilisateurs avec un navigateur lambda. Cela lui permet de mieux interpréter le contenu pour ensuite le proposer aux internautes. Sur certains sites, le rendu réel est généré de façon plus complexe, en JavaScript notamment. Mais comment Google interprète-t-il tout cela, et quelles sont les préconisations à mettre en place ? C’est ce que nous allons voir dans cet article.
 Par Daniel Roch
Par Daniel RochQu’est-ce que le rendering en SEO ?
Commençons par le commencement : le mot « rendering » s’apparente à la génération d’un élément et est un terme utilisé au départ en informatique, notamment pour les images ou les jeux vidéo (on parle par exemple de rendering 3D).
En SEO, le rendering est le fait d’obtenir une capture textuelle et visuelle d’un contenu à un instant T, c’est-à-dire en prenant en compte tous les aspects du site :
- Le texte ;
- Le code HTML ;
- Le CSS ;
- Le Javascript ;
- La technologie utilisée pour générer l’HTML ;
- Le cache ;
- Les éventuels blocages, par exemple via le fichier robots.txt ;
- Etc.
Le rendu d’une page par Google
Pourquoi Google le fait ?
Google veut depuis plusieurs années voir le contenu réel de votre site, comme le ferait n’importe lequel de vos visiteurs. Cela lui permet une bien meilleure compréhension de votre contenu (par exemple avec les éléments ajoutés en JavaScript) et une analyse plus fine de différentes problématiques techniques, comme la compatibilité mobile.
Comment Google peut-il visualiser un contenu ?
Google va crawler vos différentes URL. Il va en priorité analyser le contenu texte (le rendu HTML) et va ensuite analyser les ressources nécessaires à son affichage : le CSS et le JavaScript principalement.
Pour faire cela, Google utilisait lui-même un navigateur : Chromium en version 41. Depuis Mai 2019, Google fait appel à la dernière version de Chromium, ce qui permet d’utiliser les dernières possibilités techniques du Web (source).
Par exemple, Google pourra donc interpréter des éléments comme les variables d’environnement CSS. Vous pouvez d’ailleurs utiliser le site CanIUse pour voir ce que cela vous permettra de faire (Chrome étant une version très proche de Chromium). Par exemple, au niveau du CSS, la prise en compte des différentes méthodes et règles est bien plus complète, comme le montre l’image suivante :
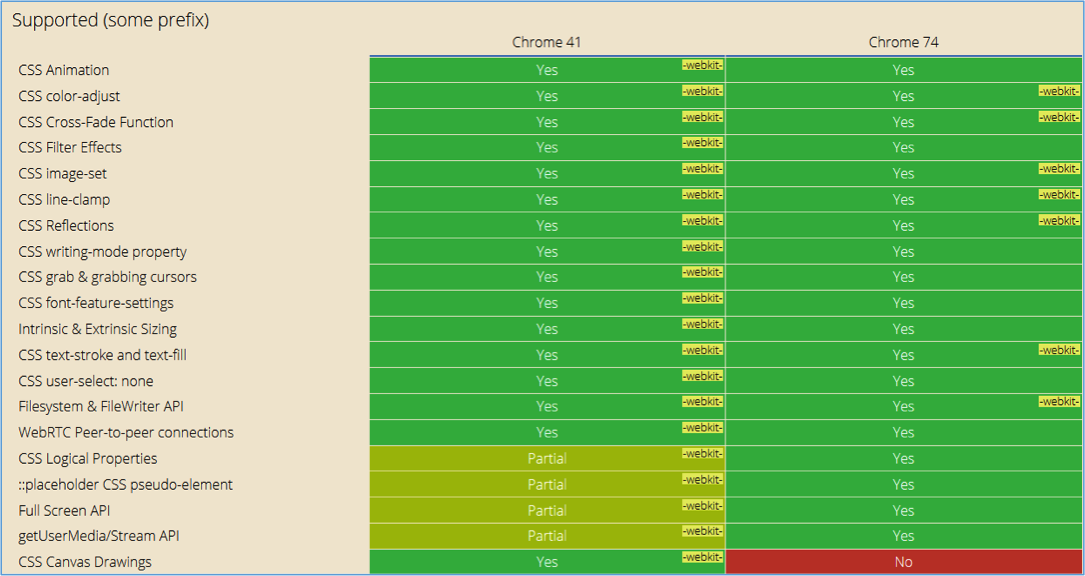
Fig. 1. Le comparatif CSS entre Chrome 41 et Chrome 74.
Mais c’est surtout au niveau des fonctionnalités récentes que l’on voit la différence, en JavaScript tout comme en CSS :
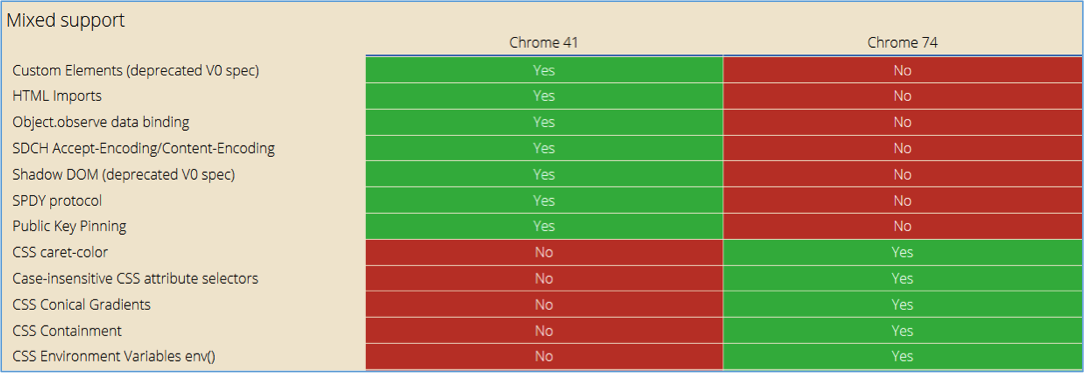
Fig. 2. Le changement est plus marqué pour les nouveautés prises en compte. Source.
Comment Google gère-t-il le JS ?
Il faut bien garder en tête que Google extrait en priorité le code HTML et ne va pas extraire systématiquement les ressources JS et CSS. On peut ainsi avoir Googlebot qui passe plusieurs fois sur le contenu HTML, mais uniquement quelques rares fois sur les fichiers JS.
![]() Daniel Roch, consultant WordPress, Référencement et Webmarketing chez SeoMix (http://www.seomix.fr)
Daniel Roch, consultant WordPress, Référencement et Webmarketing chez SeoMix (http://www.seomix.fr)














![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-527x297.png)
![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-190x190.png)
5