

En tant qu’utilisateurs du moteur de recherche Google, nous oublions parfois que derrière ces milliards de requêtes se cache toute une mécanique avancée et extrêmement pointue. Dans la majeure partie des cas, nous devons aider les algorithmes à comprendre ce que nous souhaitons exactement, bien au-delà des simples mots-clés que nous tapons dans le champ de recherche. Ce procédé passe par certaines de nos actions mais aussi au travers des divers paramètres d’URL utilisés par le moteur de recherche. Leur compréhension peut nous aider à gagner parfois beaucoup de temps au quotidien. Mais attention, tous ne sont pas visibles…
 Par Mathieu Chartier
Par Mathieu ChartierGoogle fait partie des moteurs de recherche qui préfèrent ne pas afficher tous les paramètres dont il a besoin au sein de ses URL. Ainsi, lorsque nous procédons à une recherche simple, nous voyons essentiellement des paramètres courants comme celui reprenant la requête tapée ou la page visitée au sein des centaines d’autres qui composent les pages de résultats (SERP). Voyons donc ce qui se cache derrière certains arguments d’URL, parfois obscurs pour le commun des mortels…
Quelques prérequis techniques
Avant de nous lancer tête baissée dans les paramètres des adresses de Google, nous devons comprendre pourquoi certains arguments sont visibles et d’autres non. Et surtout, dans le cas où ces paramètres sont naturellement masqués, comment se fait-il que nous puissions les voir et les connaître ?
Dans les faits, plusieurs aspects techniques expliquent comment Google peut choisir d’afficher ou masquer des paramètres. Tout d’abord, il faut différencier les requêtes de type GET (par défaut) et de type POST.
Les requêtes GET affichent les données dans les URL et permettent de facilement transmettre les informations d’une page à une autre. En effet, il suffit de récupérer le paramètre GET dans l’URL, comme par exemple le numéro de la page visitée, pour la transmettre à la page suivante, et ainsi de suite. C’est le meilleur moyen de transmettre des données non risquées, c’est pourquoi Google utilise cette méthode classique pour fournir la requête (paramètre « q », signifiant « query » en anglais) et le nombre de résultat par page (paramètre « start » qui lui permet de savoir à quel résultat les pages doivent commencer, comme « 20 » pour la troisième page par exemple).
À contrario, l’envoi de données en méthode POST masque les informations par défaut, ce qui est très pratique pour les données plus sensibles et cela permet d’éviter d’obtenir des URL d’une longueur incommensurable. Google procède ainsi pour cacher certaines informations par défaut, comme nous le verrons un peu plus loin dans cet article.
Maintenant que nous différencions les paramètres GET et POST, vous devez vous demander comment nous pouvons connaître certains paramètres cachés de Google ? Rien de magique là-dedans, nul besoin de Gérard Majax, mais simplement de deux ou trois procédés simples :
- L’utilisation des vues « en cache » de Google affiche des paramètres supplémentaires relatifs aux URL à visiter.

Fig. 1. URL referer avec paramètres provenant du cache de Google.
- La récupération des URL referers (adresses sources amenant à une page cible) en provenance de Google permettait d’afficher certains paramètres. Ce n’est plus le cas désormais.
- L’analyse des entêtes HTTP transmises à l’URL cible en provenance de Google permet également de suivre l’URL referer, mais là encore, la technique n’est plus efficace à ce jour car le moteur masque l’ensemble des paramètres pour des raisons de sécurité.
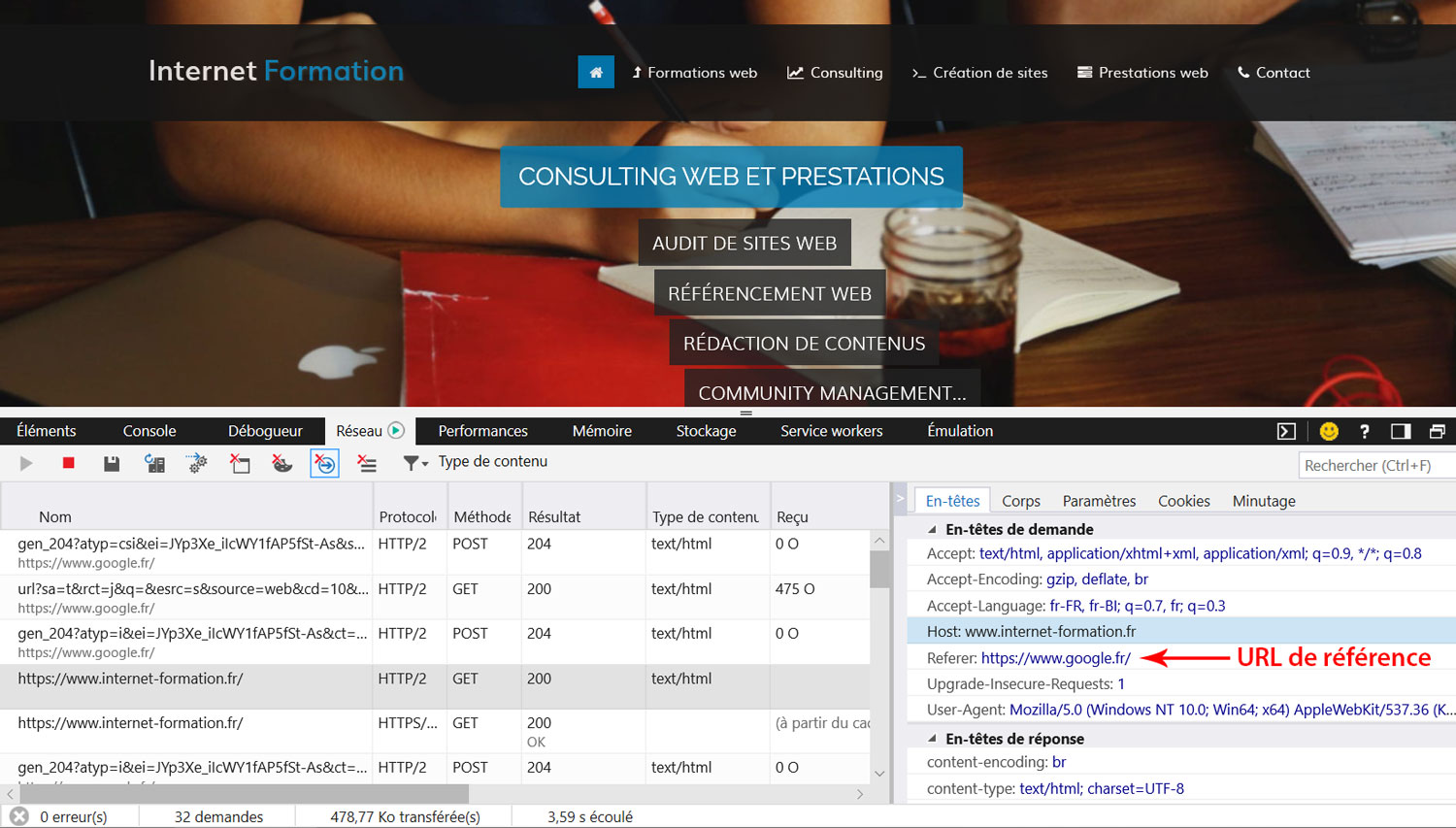
Fig. 2. Google masque les paramètres dans l’URL referer par défaut.
Historiquement, Google affichait plus de paramètres dans les URL, que l’on pouvait retrouver dans les entêtes. L’exemple suivant provient d’une URL referer provenant de Google en 2015 :
Pour des raisons de sécurité et de confidentialité, Google a transmis de plus en plus de paramètres en POST, puis a fini par modifier l’URL referer en toute circonstance par « https://www.google.com ». Cela signifie que quelle que soit la méthode, c’est toujours la même URL de référence sans paramètre qui s’affiche. Nous avons effectué des tests avec des proxies de divers pays, avec des CDN, en provenant de Google Actualités, de Google Images et bien sûr du moteur de recherche web. Dans tous les cas, le même referer ressort et ne permet donc plus d’étudier certains paramètres profonds et historiques.
Le masquage des URL referers a commencé par les liens sponsorisés en octobre 2015 (source : http://bit.ly/2KYkiIW) avant d’être discrètement appliqué aux résultats organiques dans les mois qui ont suivi. Ce n’était pas systématique dans les premiers temps, et on pouvait encore trouver des paramètres via Google Images, etc. Depuis quelques mois, c’est un masquage total et automatisé, quelle que soit la source de recherche.
Heureusement, il arrive parfois que des paramètres soient transmis par un autre biais. En effet, les outils de développement des navigateurs peuvent être d’une aide précieuse pour cela. Si nous prenons l’exemple de Microsoft Edge, vous pouvez parfois obtenir des URL avec beaucoup de paramètres sans pour autant que cela soit affiché par le biais de l’URL referer. La capture suivante montre l’URL :
Ouvrez les outils de développement (F12), allez dans l’onglet « Réseau » puis faites une recherche Google, jusqu’à la page que vous souhaitez visiter. Lors de l’ouverture, la première information affichée dans les outils de développement est la requête HTTP ou HTTP/2. En cliquant sur cette dernière, on obtient le détail de l’URL de provenance de Google, avec quelques paramètres tels que la source ou l’URL ciblée. Dans l’exemple précédent, on note que la source est « newssearch », à savoir que la recherche provient de Google Actualités (on peut trouver des sources comme « maps », « video » ou « web » pour les autres types de recherche).
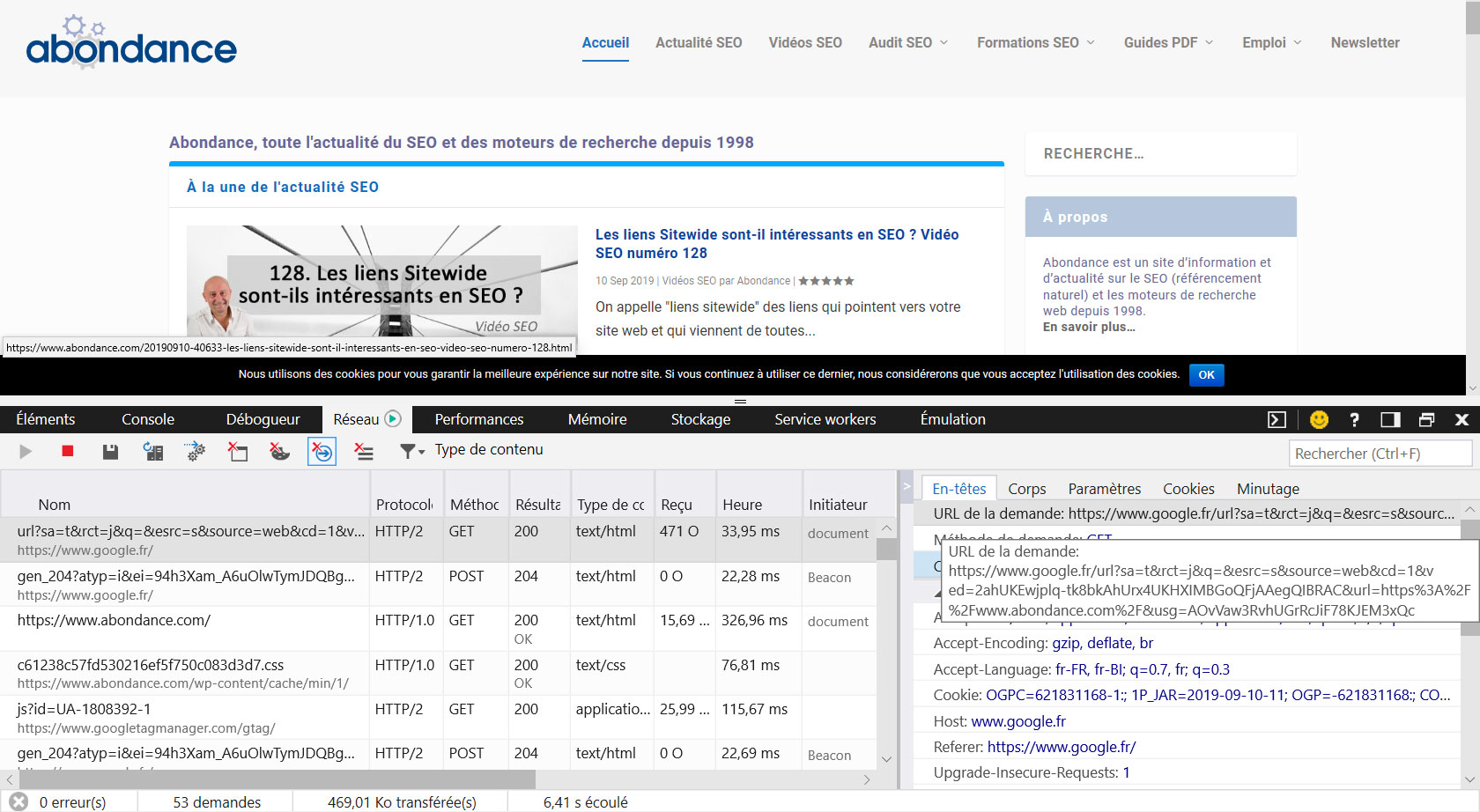
Fig. 3. Affichage de paramètres d’URL dans les données réseaux d’Edge.
Du paramètre « q » au « not provided »…
S’il est possible d’attribuer la suppression des paramètres informatifs dans les URL de référence à la sécurité, l’histoire a été bien différente dans les faits. En effet, à l’origine, c’est la volonté de Google de masquer les requêtes tapées par les internautes qui a induit ce genre de procédé.
Depuis 2011, le moteur de recherche a commencé à afficher des « not provided » en lieu et place des mots clés dans Google Analytics. Nous n’avons jamais vraiment su la réelle volonté de Google de cacher uniquement les mots clés tapés par les internautes mais cela laisse penser que l’objectif était d’inciter les webmasters à passer par Google Adwords (devenu Google Ads depuis) pour pouvoir suivre les clics sur tels ou tels mots clés.
Le paramètre « q » (pour « query ») est le paramètre qui transmet les mots clés tapés par l’internaute lors de sa recherche. Ce dernier est primordial mais ne présente pas de risques fondamentaux pour la sécurité (pour la confidentialité éventuellement). Du jour au lendemain, Google a supprimé ce paramètre et s’est caché derrière mille excuses pour expliquer ce retrait. Si vous reprenez les URL présentées à la fin de la section précédente, vous noterez que seul le paramètre « q= » n’a pas de valeur, là où absolument tous les autres en ont. Cela démontre bien que Google avait volontairement choisi de ne pas afficher les mots clés, et uniquement eux. D’ailleurs, pour l’anecdote, nous pouvions encore faire des recherches en HTTP à l’époque (Google ne forçait pas l’usage d’HTTPS) et dans ce cas, les URL transmettaient bien les mots clés, comme dans l’exemple suivant (pâle copie de l’exemple précédent de 2015, mais en HTTP) :
Bref, le paramètre « q » est désormais uniquement affiché dans les URL lors du fonctionnement des SERP, mais plus du tout transmis dans les URL de référence ni entêtes HTTP. Les « not provided » ont depuis été propagés totalement et seule la nouvelle Google Search Console permet d’obtenir des informations sur les requêtes tapées, preuve une nouvelle fois que Google ne masque les données que pour les utilisateurs…
Typologie des paramètres
En soi, nous pouvons classer les arguments d’URL en plusieurs grandes familles :
- Paramètres fonctionnels : ils ont pour objectif d’aider le moteur à fonctionner comme il se doit. Par exemple, le paramètre du numéro de page tient un rôle important pour que le moteur restitue les bons résultats dans les SERP (cela va de soi…).
- Paramètres de suivi/tracking : ils sont utilisés pour Google afin d’obtenir des datas sur les recherches, sur le comportement des utilisateurs (clics sur tel ou tel liens, dans telle ou telle zone de la page, etc.) ou encore sur les sessions en cours.
- Paramètres d’interface : ils servent à gérer des fonctionnalités avancées du moteur, disponibles aussi par le biais d’options disponibles dans les outils, etc.
- Paramètres « additionnels » : Google dispose de certains add-ons inaccessible autrement que par l’URL directement, mais ces paramètres évoluent avec le temps (création/suppression au fil des ans).
Nous ne catégoriserons pas forcément l’ensemble des paramètres que nous allons vous présenter, nous vous laissons le soin de les classer par vous-mêmes si nécessaire. Toutefois, vous devriez rapidement repérer dans quelle catégorie ira chaque argument présenté dans la suite de cet article…
Les paramètres visibles
Nous sommes entrés dans le vif du sujet avec le paramètre « q » et ses spécificités. Qu’en est-il maintenant des autres paramètres visibles directement dans l’URL lors d’une recherche ? En effet, après avoir tapé nos premiers mots clés et validé la demande, l’URL générale se remplit de paramètres, dont certains semblent même cryptés, comme dans cette exemple :
https://www.google.com/search?client=firefox-b-d &ei=hx9lXZSRJYqIlwTE9bHQBg&q=param%C3%A8tres+url+google+bih+sa&oq=param%C3%A8tres+url+google+bih+sa &gs_l=psy-ab.3..33i21j33i160.12756.15213..15341…0.2..0.121.638.5j2……0….1..gws-wiz…….0i71j33i22i29i30.TJougRB6TPs &ved=0ahUKEwjU8OuihKPkAhUKxIUKHcR6DGoQ4dUDCAo&uact=5
Comme cela ne vous suffit pas (si, admettez-le ! 🙂 ), voici la forme de l’URL pour la même recherche, mais cette fois-ci dans les pages suivantes des SERP :
Vous pouvez d’ores-et-déjà constater que Google ne transmet pas tous les paramètres de la première SERP aux autres pages de résultats, et que certaines nouvelles données apparaissent. On peut se demander pourquoi, mais la raison est nécessairement fonctionnelle, et seuls les paramètres totalement utiles pour continuer la recherche sont transmis en GET, les autres ayant sûrement une vie souterraine en POST…
Si nous allons plus loin, il peut être intéressant de passer par la recherche avancée pour mieux comprendre certains paramètres. Dans ce cas, tous les arguments sont préfixés avec « as_ », signifiant « advanced search ». On retrouve ainsi des paramètres qui dépendent de votre configuration, comme le choix de la langue, de la période utilisée, du type de requête, etc.
Tentons alors de détailler quelques-uns de ces arguments d’URL :
- Première page de résultats :
- hl : signifie certainement « home language », donc le code langue d’origine (« fr » pour la France).
- source : type de source originelle de la recherche. Cela peut être les sources classiques comme « newssearch », « images », « video », « web » mais aussi « hp » (pour « homepage »), etc.
- ei : certainement un paramètre de suivi (tracking) pour Google, différent pour chaque recherche.
- q : requête finale, après l’avoir tapé ou avoir cliqué sur une suggestion.
- oq : requête originelle tapée par les utilisateurs avant d’opter (ou non) pour une suggestion de recherche (c’est donc parfois la requête non terminée puisque l’on clique sur la suggestion avant).
- gs_l : ce paramètre, crypté en apparence, semble fournir des données sur le type de support utilisé (on retrouve toujours le schéma « mobile-gws-wiz-SOURCE » sur mobile par exemple) et sûrement sur la géolocalisation de la recherche (coordonnées cryptées peut-être…).
- ved : semble être un identifiant de session, sûrement utile pour le tracking de Google. Il semblerait que la valeur de « ved » dépende aussi du navigateur utilisé, ce qui permettrait à Google de déterminer la part de visite par outil.
- uact : impossible de déterminer le rôle de ce paramètre qui n’apparaît pas dans tous les cas et dont la valeur semble toujours « 5 ». Tous les tests effectués avec d’autres valeurs n’ont pas été probants…
- Autres pages de résultats :
- start : numéro du premier résultat de la page, donnant ainsi le numéro de page visitée parmi les centaines de pages de résultats (dans l’exemple, « start=20 » signifie qu’on se trouve en troisième page des SERP).
- sa : type de liens cliqué dans la SERP, sûrement traduisible par « search action ». Par exemple, « sa=N » signifie que l’on clique sur les liens de navigation en bas de page (pagination), tandis que « sa=X » correspond à tous les autres types de clics (recherche par actualités, par images, par Maps…)
- bih : hauteur du viewport (fenêtre de l’appareil utilisé).
- biw : largeur du viewport, utile pour déterminer si Google Mobile doit être utilisé ou non. Si vous effectuez le test en vue adaptative dans un navigateur, vous remarquerez que Google bascule en version mobile en-dessous d’une certaine résolution.
- Autres paramètres (via la recherche avancée ou les paramètres avancés notamment) :
- lr : langue de la recherche (« lang_fr » pour le français)
- tbs : signifie sûrement « time before search » et prend plusieurs valeurs sous la forme « qdr:VALEUR » (« qdr » semble signifier « query duration »). Si vous limitez à la dernière heure, la valeur est « h ». Les autres valeurs sont « d » (day) pour les 24 dernières heures, « w » (week) pour l’ultime semaine, « m » (month) pour le dernier mois et fort logiquement, « y » (year) pour la dernière année.
- tmb : type de recherche. Par exemple « tbm=bks » (pour « books ») recherche dans les livres, « nws » pour les actualités, « vid » pour les vidéos, « shop » pour Shopping, « isch » pour les images (…) ou encore « pts » pour les brevets (équivalent de Google Patents). Le plus curieux est « tbm=map » qui fait télécharger un fichier texte rempli de données étranges, là où toutes les autres valeurs retournent une page d’erreur…
Tous les paramètres n’ont pas pu être détaillés et peuvent varier quelque peu selon le navigateur utilisé, mais ceux-ci semblent être les plus courants. On note la diversité des paramètres existants, sachant qu’avec la recherche avancée, vous pouvez en obtenir une toute nouvelle liste dépendant des paramètres que vous avez entrés lors de votre recherche. D’ailleurs, certains paramètres de la recherche avancée n’existent que dans ce contexte. Si par exemple vous cherchez uniquement des fichiers PDF, la recherche avancée va générer le paramètre « sa_filetype=PDF ». Si vous testez ce paramètre dans une recherche classique sous la forme « filetype= » ou même « sa_filetype= », ce dernier ne fonctionnera pas. Les équivalents se trouvent dans des fonctionnalités avancées à taper dans le champ de recherche, comme « filetype:PDF », « intitle:MOT », etc.
Les paramètres masqués et fonctionnels
Nous avons fait le tour de la très large majorité des paramètres affichés explicitement par le moteur de recherche, mais qu’en est-il de tous les autres paramètres existants ? Les paramètres masqués sont à la fois des paramètres de suivi, fonctionnels ou additionnels. Google en masque certains car ils sont inutiles pour l’utilisateur, ou sinon parce qu’il s’agit de fonctionnalités optionnelles ou additionnelles, donc inintéressants au premier abord pour la grande majorité des usagers.
On retrouve par exemple des arguments comme « sig » ou « usg » qui servent très certainement à du tracking, au même titre que « ei » voire « ved » que nous avons déjà présentés. On peut ajouter à cela le paramètre « cd » qui revêt une importance capitale pour nous. En effet, « cd » sert à indiquer la position du résultat dans la SERP, avec une numérotation pure et simple. En théorie, « cd=3 » signifie donc que le résultat cliqué est le 3e de la liste présentée par Google.
Il existe des moyens de filtrer à la volée cette donnée dans Google Analytics pour faire remonter les positions des résultats en fonction des mots clés tapés. Avec la propagation du « not provided », cela a perdu un peu d’intérêt mais on peut très bien s’amuser à faire remonter l’information en fonction des pages de destination, ce qui donnerait une idée de la position de chaque page…
Le paramètre « cd » est l’un des rares paramètres masqués de suivi qui est exploitable pour les SEO. Son intérêt est majeur tant le suivi du positionnement compte dans ce métier. Toutefois, il convient de relativiser la valeur fournie par Google, notamment depuis la mise en place des tous derniers blocs affichés dans les SERP (Position 0, Answers box, Maps box, etc.). En effet, la valeur retournée par le paramètre « cd » n’est pas toujours celle que l’on constate de nos propres yeux lors des tests.
Plusieurs phénomènes peuvent expliquer un léger décalage entre la donnée remontée et ce qu’on voit en réel :
- La position serait celle enregistrée au moment de la mise en cache de la page par Google. Ainsi, avec les mouvements habituels (notamment dans les requêtes d’actualités), la position notifiée est peut-être différente de celle visible.
- Le paramètre « cd » ne tient pas compte de la géolocalisation, des paramètres personnalisés, de l’historique des recherches (…) et tout ce qui peut affecter l’ordre des résultats dans les SERP pour chaque utilisateur. Il s’agit alors de la position « universelle » et non celle vue dans un contexte particulier.
- La position dépend des blocs affichés dans la page. Par exemple, il est fréquent qu’une Position 0 soit considérée comme 3 positions dans la SERP. De même, un bloc « vidéos » peut afficher jusqu’à 10 vidéos, soit autant de positions. Dans un exemple de test sur la requête « cocktail mojito », le premier résultat organique, situé juste après une Position 0 et un bloc « vidéos » prend donc la position 14, alors qu’on pourrait penser qu’il s’agit de la position 1 naturellement. Pour l’anecdote, même le bloc « Performances de recherche pour cette requête » affiché uniquement pour les comptes Search Console connectés occupe une position…
- Une autre théorie semble se confirmer en imaginant que Google « découpe » la page en pixel et qu’il attribue une position également en fonction de la zone dans laquelle se trouve un résultat. On observe de plus en plus le phénomène de longueur en pixels des SERP, donc cette théorie pourrait être crédible pour mieux comprendre les chiffres parfois alambiqués du paramètre « cd ».
La question que l’on peut se poser est la pertinence actuelle du paramètre « cd », sûrement utilisé par la Google Search Console pour afficher la position moyenne d’un résultat sur une requête donnée (dans le rapport « Performances »). En effet, Google possède-t-il un autre moyen d’obtenir la réelle position du résultat en fonction du type de SERP, ou se base-t-il simplement sur ce facteur ? Si oui, alors la valeur de la position moyenne est totalement faussée. Seules les requêtes purement textuelles obtiennent une valeur juste, tous les autres blocs perturbent la valeur du paramètre « cd » et trompent l’usager…
Sachant cela, il devient très compliqué de connaître la position réelle d’un résultat, notamment dans la première page de résultats. Souvent, dès la seconde page de résultats, les positions redeviennent « normales ». Il est fréquent qu’après avoir vu un résultat affiché comme 45e dans la première page, on retrouve l’ordre logique des 11e, 12e, 13e (…) résultats dès le début de la seconde page, car la recherche universelle ne fait plus son œuvre en règle générale. Ironie du sort, ce que l’on appelle « Position 0 » ne retourne jamais un « cd=0 », peut-être devrions-nous changer de nom ? 🙂
Cela signifie qu’un résultat affiché avant un autre peut sembler avoir une position en apparence supérieure à celle qui suit. Pour cet article, le test a été effectué avec la requête d’actualités « G7 » qui avait lieu dans le sud-ouest de la France fin août 2019. Ici, la requête permet d’étendre la recherche universelle au-delà de la première page. Par conséquent, l’ordre de classement est « faussé » en première page, puis reprend bien à 11 en seconde page, avant d’être à nouveau trompé par un blog d’images (qui occupent 10 positions), et enfin de reprendre son cours normal en troisième page à la 21e position, etc.
Ce type de comptage montre qu’il faut aller plus loin qu’une simple analyse du paramètre « cd », il convient aussi de vérifier à quel type de SERP nous avons affaire pour chaque requête testée, et selon le contexte de recherche (période, heure, géolocalisation, connexion ou non à un compte, etc.). Il devient donc quasiment impossible de mesurer précisément la position d’un résultat sans l’ensemble de ces informations.
Nous pouvons émettre certains doutes sur le suivi des positions effectué par certains outils qui n’iraient pas en profondeur dans l’analyse de tous ces critères à suivre. Il conviendrait d’analyser les SERP en les crawlant, tout en se prémunissant contre les différents blocages de Google, tout en distinguant les résultats organiques des autres formes de réponses. C’est possible mais complexe et coûteux (il faut des proxies pour contourner les systèmes de détection de spam de Google, etc.), et tous ne peuvent pas se le permettre. Il est fort à parier que plusieurs outils fournissent donc une vision tronquée du positionnement, notamment si le paramètre « cd » est mal exploité.
D’après tous les tests que nous avons effectués, les différents blocs affichés dans les SERP occupent en général 1 (réponse directe, bloc pour webmasters, etc.), 3 (bloc d’adresses, Position 0, etc.) et 10 positions (images, vidéos, etc.). Autre changement à noter, les sitelinks (liens affichés sous un domaine principal lorsque la requête est basée sur le nom de l’entreprise ou de la marque) sont également comptabilités. En général au nombre de 4 ou 6, le résultat suivant voit donc la valeur de « cd » repoussée d’autant de positions. Seuls les liens sponsorisés sont toujours ignorés en revanche, comme cela a toujours été le cas.
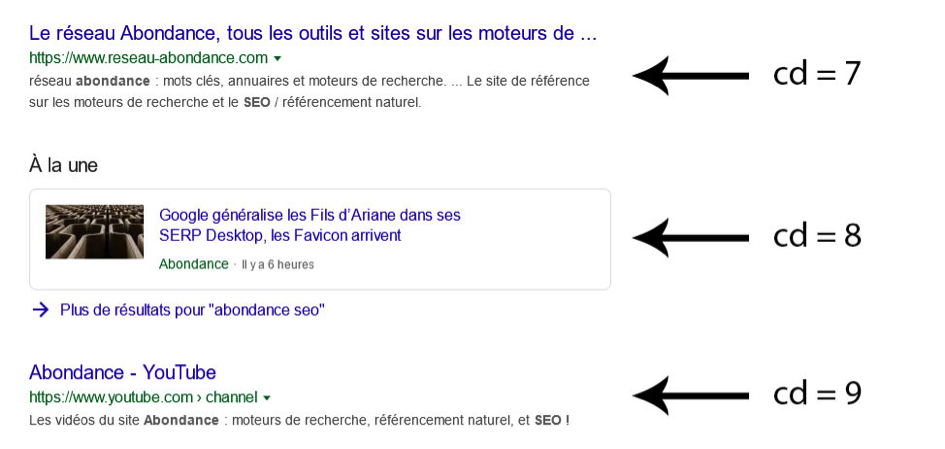
Fig. 4. Décompte du paramètre « cd » dans les SERP.
Dans quelques cas de carrousels présents dans les SERP, le décompte se fait mal ou bizarrement par Google (voir l’exemple de la capture suivante). En effet, alors qu’un bloc peut afficher 4 résultats différents dans le carrousel, Google en compte 5 avant le résultat qui suit. D’après les tests réalisés, il semblerait que Google puisse recompter un résultat qui s’affiche dans plusieurs défilements de carrousel, d’où ce décalage…
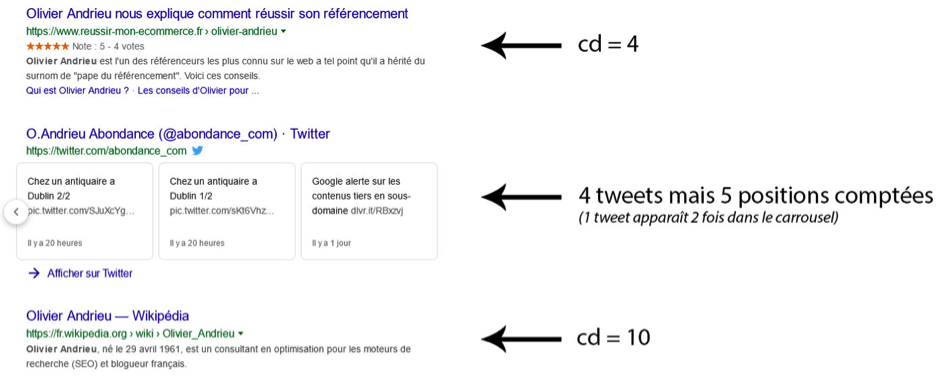
Fig. 5. Le comptage parfois surprenant du paramètre « cd ».
Malgré l’analyse de centaines de requêtes différentes, aucun paramètre ne permet de clairement différencier le type de résultats en fonction du bloc cliqué. Une Position 0 provient d’une source « web », tout comme un résultat organique classique, donc il est impossible de déterminer si le paramètre « cd » est relatif à un résultat naturel ou à un élément de la recherche universelle. Lorsque l’on clique sur un lien « site web » dans un bloc d’adresses Google Maps, là encore la source est « web » (elle devient « local » lorsque l’on passe par Google Maps en lui-même, mais pas via les SERP).
Par conséquent, voici un paramètre fort intéressant qui mérite une attention toute particulière tant son comptage dépend de la recherche universelle mais aussi de la pagination en cours. Autrefois très pratique pour les résultats textuels, il devient quelque peu mensonger dès que d’autres types de résultats apparaissent dans les pages. Passons donc aux paramètres d’URL bien plus clairs et directs.
Quelques paramètres complémentaires et optionnels
Nous n’avons pas traité les paramètres additionnels et fonctionnels dans la section précédente, il nous semblait plus intéressant de les séparer du cas particulier de « cd » et des quelques arguments de tracking repérés ci et là.
Voyons déjà quelques paramètres de fonctionnalités que l’on peut ajouter dans nos URL de recherche (à valider bien entendu en chargeant la recherche modifiée), dont certains peuvent se retrouver dans les paramètres de recherche :
- newwindow (0 ou 1) : si la valeur 1 est donnée, les résultats s’ouvrent dans un nouvel onglet.
- safe (on ou off) : la valeur « on » active le safe mode de Google, qui retire tous les résultats risqués pour les enfants, etc. On retrouve aussi le paramètre « safeui=on » parfois, voire « safe=active », donc plusieurs valeurs sont peut-être autorisées…
- pws (0 ou 1) : active la recherche personnalisée ou non.
- num (chiffre) : détermine le nombre de résultats à afficher par page, jusqu’à 100.
- filter (0 ou 1) : filtre les recherches similaires.
- adtest (on ou autre) : permet de passer en mode test pour les annonces. Ainsi, les résultats payants ne sont plus cliquables (pas de redirection ni de prise en compte du clic), mais les annonceurs peuvent vérifier leur affichage sans risque.
Dans Google Images, vous pouvez également ajouter le paramètre « sout » pour changer l’interface. Si vous entrez « sout=1 », vous retrouverez l’interface historique de l’outil de recherche pour images. Voyez ce joli bon dans le passé dans la capture suivante.
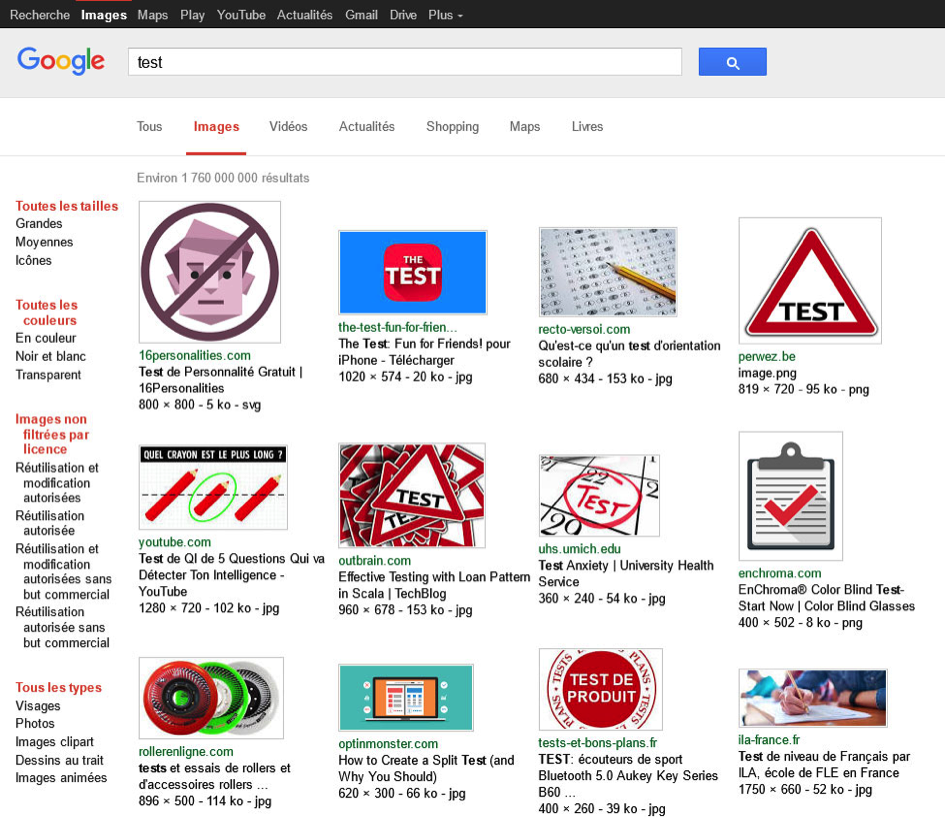
Fig. 6. Exemple de changement d’interface de Google Images avec le paramètre « sout ».
Enfin, quelques paramètres sont pratiques pour contourner quelque peu la géolocalisation forcée par Google. En effet, tous les résultats sont automatiquement situés dans la zone relative à votre adresse IP ou votre puce GPS. Google va même jusqu’à appliquer ce procédé si vous testez des versions de Google différentes comme google.co.uk, etc. Par conséquent, il devient difficile de tester des résultats provenant de zones géographiques différentes de la vôtre. Pourtant, quelques paramètres d’URL peuvent nous aider :
- cr (countryXX) : en remplaçant « XX » par un code de pays (« FR » pour la France, « IT » pour l’Italie, etc.), nous obtenons les résultats pour un pays donné (mais pas forcément la langue du pays).
- lr (lang_XX) : « XX » prend le code langue d’un pays pour afficher uniquement les résultats dans la langue demandée (exemple : « lr=lang_it » pour l’italien).
- gl (XX) : « XX » correspond au code du pays et permet de modifier le pays source de la recherche. Par exemple « gl=GB » indique « Royaume-Uni » en bas de page, alors que la France est automatiquement détectée par défaut. Il est généralement à combiner avec les autres paramètres, notamment « cr », pour changer le comportement de recherche.
- near (nom de ville) : ce paramètre, introuvable dans les options par défaut, permet d’indiquer un nom de ville autour de laquelle vous souhaitez effectuer votre recherche. Il est intéressant à coupler avec les autres paramètres de géolocalisation pour être plus précis.
En soi, si vous combinez plusieurs de ces paramètres, voire des options avancées de recherche par langue ou pays, vous devriez pouvoir mener des recherches sans la géolocalisation forcée par Google. La capture suivante montre l’exemple d’une recherche effectuée en France et qui affiche pourtant des résultats du Royaume-Uni, et plus précisément autour de Londres grâce au paramètres « near=london » (la langue n’a volontairement pas été modifiée pour montrer que l’on peut vraiment personnaliser la recherche).
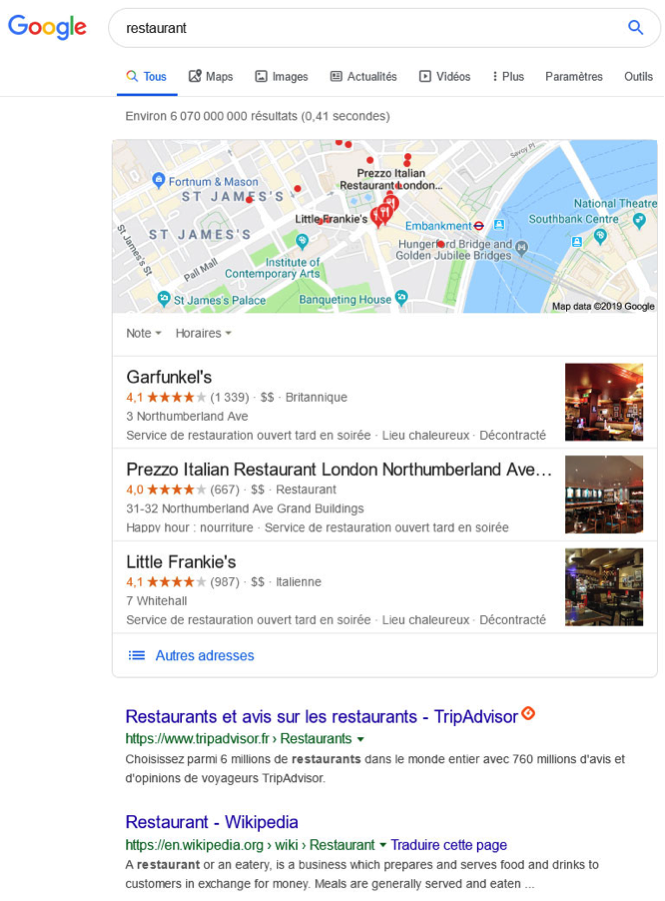
Fig. 7. Recherche avec géolocalisation modifiée manuellement avec « near ».
Vous savez désormais presque tout sur les paramètres d’URL utilisés dans le Google de 2019. De nombreux articles sur le sujet existent mais peu sont à jour ou prennent en compte tous les arguments présentés ici. En effet, Google modifie sans cesse ses fonctionnalités internes, ses paramètres mais aussi son interface. Par conséquent, de nombreuses possibilités apparaissent et disparaissent dans les méandres du moteur (ou dans les paramètres transmis en POST et donc masqués par défaut), il est donc difficile de se maintenir à jour sur ce point. Il est même fort à parier que d’autres paramètres méconnus comme « near » existent sans que nous le sachions vraiment. Quoi qu’il en soit, nous espérons que ce tour d’horizon vous aura éclairé et plu, et que ces paramètres n’auront rapidement plus de secret pour vous… 😉
![]() Mathieu Chartier
Mathieu Chartier
Consultant-Formateur et webmaster indépendant, Internet-Formation (https://www.internet-formation.fr)















5