

La recherche d’images peut revétir plusieurs formes : texte (requête) vers image, image vers image (similarité) ou image vers page web. Dans tous ces cas, des technologies existent aujourd’hui et sont appliquées, souvent avec un bonheur certain, par de nombreux moteurs de recherche. Sylvain Peyronnet, qui a créé le moteur de recherche d’images de Qwant, nous explique dans cette série d’articles ce qui se passe “sous la carrosserie du moteur” et les différents algorithmes utilisés, avec des explications les plus… imagées possible.
 Par Sylvain Peyronnet
Par Sylvain Peyronnet
Ce mois-ci et le mois prochain, je vais aborder un point qui n’est pas couramment évoqué lorsque l’on parle du fonctionnement des moteurs de recherche, il s’agit de la verticale “images”. Vous remarquerez que je prends une précaution littéraire en parlant de “verticale images” et non pas de moteur de recherche image, car le sens que l’on peut donner à cette dernière expression est multiple.
En effet, on peut s’intéresser à :
- Un moteur de recherche qui prend en entrée un texte comme requête, et renvoie en sortie des images ;
- Un moteur de recherche qui prend en entrée une image, et renvoie en sortie des images.
- Un moteur de recherche qui prend en entrée une image, et renvoie en sortie des pages web (qui contiennent l’image, ou plus impressionnant qui parlent de ce qui est représenté dans l’image).
Aujourd’hui, la technologie est assez mature pour assurer ces trois missions, et c’est pour cela que le terme “moteur de recherche images” est et reste assez flou.
Comme souvent, les anglo-saxons sont un peu plus précis : ils font la distinction entre plusieurs objets, et utilisent les termes de image retrieval system pour désigner un moteur qui renvoie des images en sortie, de image meta search pour dire que le moteur se base sur une information hors de l’image, et de content-based image retrieval pour signifier que c’est le contenu réel de l’image qui est utilisé.
Dans cette série d’articles, nous allons évoquer tout cela.
Première question : un moteur “images”, pour qui ? pour quoi faire ?
Comme souvent, la définition technique d’un produit va découler de ses cas d’usage. La première question que l’on va donc se poser est celle de l’utilisateur du produit de recherche d’images, et de son intention.
On remarque dans la figure 1 tirée de l’article [1] que le nombre de domaines d’applications de la recherche d’images est bien plus important qu’on ne le croit, avec des utilisations dans des domaines comme la sécurité (la reconnaissance faciale est de la recherche d’images), l’art et bien entendu le Web.
Par ailleurs, il faut se poser la question de qui est l’utilisateur, même dans le cadre web. Il y a par exemple une utilisation évidente avec madame ou monsieur Lambda qui veut voir des photos de l’interlocuteur, son prochain rendez-vous de boulot, ou voir les photos d’un acteur, etc. Mais il y a aussi le cas de l’entreprise de vente en ligne qui veut proposer des produits similaires à ceux que vous avez pris en photo chez un ami. Deux usages très différents qui amènent à l’utilisation d’algorithmes et technologies différentes.
Par ailleurs, on peut évoquer un dernier cas, pas nécessairement relié au web, qui est celui de la recherche de visuels pour illustrer des contenus rédigés. Là encore, une autre intention (informationnelle au sens premier du terme) en ressort et donc d’autres technologies.
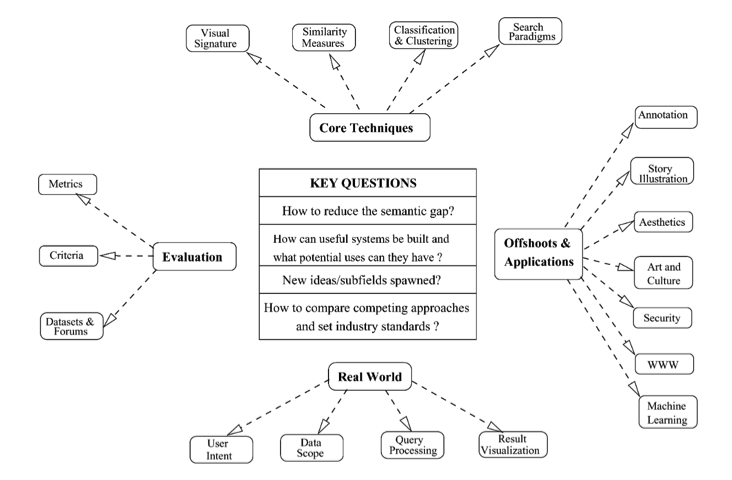
Fig. 1. Le contexte d’un moteur “images”, tiré de l’article [1].
Un autre aspect à prendre en compte est celui de la provenance des images : aujourd’hui, Google et Bing proposent des images venues du Web dans son intégralité (hors plateformes fermées), mais d’autres moteurs se concentrent sur les réseaux sociaux (SIRE par exemple [2]), ou sur des collections d’images totalement fermées (moteur de recherche personnel ou d’entreprise, pour chercher dans ses photos de famille ou documentaires).
Il y a là aussi un impact : sur la structuration des données, sur la facilité à avoir un feedback utilisateur (pour de la recherche personnelle, l’utilisateur est prêt à “travailler” plus), sur la capacité à agréger de la meta-information supplémentaire, etc.
Utiliser de la donnée textuelle pour trouver des images
La manière la plus simple de faire un moteur de recherche qui renvoie des images est en fait d’utiliser le moteur standard de recherche sur du texte en le modifiant pour qu’il renvoie des images.
Concrètement, toute l’astuce est donc de créer un index d’images avec des meta-données qui caractérisent ces images. La recherche se fera en mode “standard” sur ces meta-données.
La seule question est alors de savoir quelles sont les données que l’on peut obtenir sur des images disponibles librement sur le web. Quand on dresse une liste, on voit qu’en fait, une image est généralement plutôt bien dotée de ce point de vue :
- Il y a bien entendu le nom du fichier, et si un SEO est passé par là, un attribut ALT bien rempli (c’est important ! et de plus, c’est bien pour l’accessibilité).
- Il existe des meta-données liées à la photo elle-même, vous pouvez faire le test avec vos propres photos sur un des nombreux sites qui proposent de visualiser les données des photos (par exemple http://metapicz.com/#landing). Parmi celles-ci : la localisation géographique de l’endroit où vous avez pris la photo, la date et l’heure de la prise de vue, l’appareil photo, le logiciel utilisé, éventuellement des données sur l’auteur de la photo, la résolution, le mode vertical ou horizontal, etc.
- Une image est rarement seule sur le Web : elle évolue dans un contexte textuel avec des phrases qui la décrivent, qui l’entourent. Ces contenus textuels sont associés à l’image dans l’index. C’est la plus grosse source de données. Cela veut aussi dire que l’on peut assez facilement manipuler les moteurs de recherche d’images standards que l’on trouve chez les principaux moteurs. Il suffit de créer des pages qui encapsulent les images dans des textes bien choisis, avec attribut ALT et nom du fichier bien adapté.
- Enfin, la dernière source de données textuelles associées à une image est constituée d’éventuelles annotations humaines. Tous les moteurs à échelle industrielle vont procéder à de l’annotation d’images. Pas forcément systématiquement (nous verrons plus tard pourquoi ce n’est pas nécessaire) mais à grande échelle tout de même. Ces annotations peuvent être des descriptions exhaustives, ou tout simplement des tags représentatifs des éléments les plus importants évoqués dans les images (par exemple des noms de personnes connues).
A partir de toutes ces données textuelles, il est alors possible de faire facilement une recherche d’images raisonnablement efficace, mais assez facile à manipuler coté SEO. La qualité des SERP images sera largement similaire à la qualité des résultats usuels du moteur, puisque les mêmes algorithmes et technologies sont utilisés pour les deux tâches.
Utiliser une image pour trouver des images
Dès les premières années de la recherche sur le web (voir l’article [3], qui présente le système QBIC par IBM et qui date de 1995), les chercheurs ont mis en place des algorithmes pour chercher des images à partir d’une image (recherche par similarité).
Il est intéressant de noter qu’à l’époque, les techniques utilisées (voir figure 2) sont des techniques classiques de vision par ordinateur et sont vraiment trop coûteuses en terme de temps de calcul pour pouvoir être utilisées de manière industrielle.
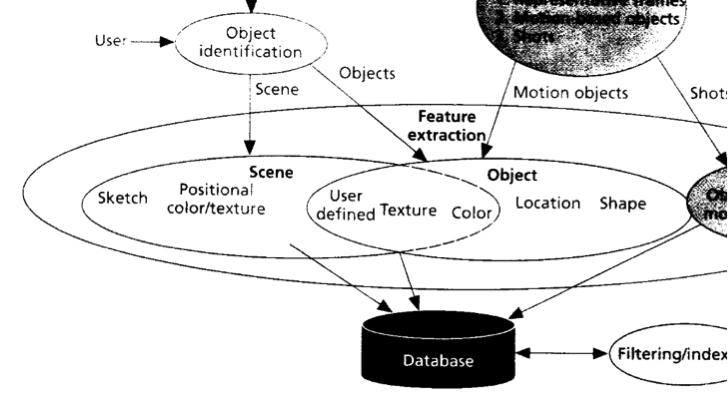
Fig. 2. Les caractéristiques visuelles utilisées pour la recherche par similarité (tirée de l’article [3]).
D’un point de vue intuitif, à l’époque, la distribution des couleurs et des formes dans l’image, ainsi que la détection des arêtes saillantes, dont les principales caractéristiques utilisées pour reconnaître des images similaires. Le cas d’usage théorique est de mettre une image et de récupérer des images qui contiennent les mêmes objets. Inutile de dire qu’à l’époque, les résultats étaient mitigés.
En revanche, depuis quelques mois, on note l’apparition d’un grand nombre d’outils qui font de la recherche d’images par similarité. Pour la petite histoire, c’est la première brique que nous avons développé dans le cadre du projet QISS chez Qwant (voir l’article [4]).
Tous ces nouveaux outils sont compatibles avec une vraie industrialisation et peuvent mener à des produits commerciaux (pour le e-commerce par exemple). Ceci est faisable grâce à l’essor des méthodes à base de réseaux de neurones, et sont utilisées parce qu’elles évitent de passer par la qualification humaine d’un dataset (il n’est alors pas besoin d’avoir des images annotés pour démarrer le service).
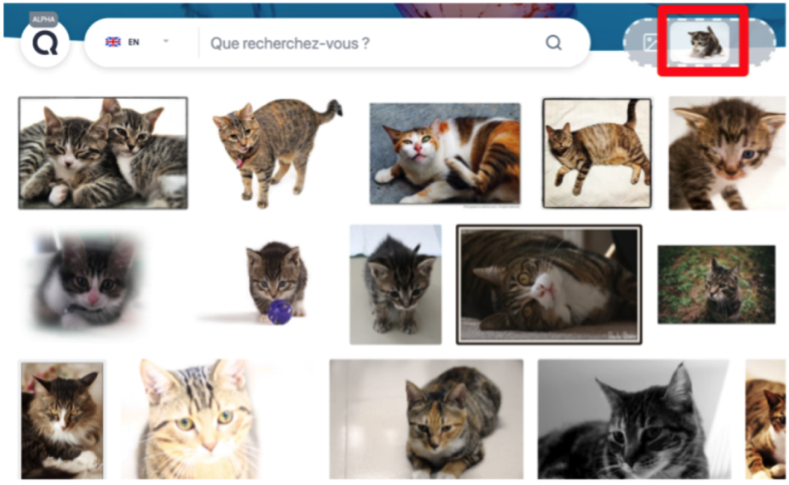
Fig. 3. Recherche d’images similaires dans Qwant QISS (prototype disponible à l’adresse https://research.qwant.com/images/).
Concrètement, pour réaliser de manière moderne du rapprochement d’images similaires, il faut tout d’abord extraire des caractéristiques visuelles avec un modèle de réseaux de neurones spécifiques. La plupart des gens utilisent ResNet pour cela (residual networks). Nous avons utilisé ResNet-152, qui a été pré-entrainé pour apprendre les bonnes caractéristiques sur plus d’un million d’images de 1 000 catégories. Cela permet de comprendre des images très diverses. Une fois les caractéristiques extraites, nous créons une signature à l’aide d’une autre technique (le pooling WELDON, créée par des chercheurs de l’Université Paris 6), qui détecte les endroits importants d’une image pour encoder seulement les informations déterminantes. Par exemple, si une image présente un chat sur un fond uni blanc, l’algorithme va se concentrer sur les parties de l’image où l’on voit le chat.
D’un point de vue efficacité, si on prend une plateforme matérielle moderne et puissante (DGX chez NVidia, IPU chez Graphcore), on peut mettre en production sans aucun souci ce type de méthode. En terme de SEO, il est pour l’instant quasiment impossible de manipuler les résultats. La théorie dit que c’est possible et des chercheurs l’ont d’ailleurs prouvé : on peut ajouter de l’information “invisible” qui va modifier les paramètres des caractéristiques extraites par ResNet. Mais cela demande un niveau de technicité particulièrement élevé et c’est donc pour l’instant hors de portée des SEO traditionnels et des spammeurs web. A noter qu’on trouve des méthodes très proches chez d’autres opérateurs (tinEYE, duplichecker, etc.).
La question que nous allons nous poser maintenant est : est-ce qu’on peut utiliser la brique de recherche textuelle pour les images et la recherche d’images similaires simultanément pour obtenir de meilleurs résultats sur un moteur de recherche d’images qui soit “full scale“, c’est-à-dire à l’échelle du web dans son intégralité ? Mais ceci, vous le saurez le mois prochain. Vous découvrirez par ailleurs comment on fait de la recherche dans les images directement, et dans plusieurs langues simultanément.
Bonne recherche d’images d’ici là et rendez-vous le mois prochain !
Références
[1] Datta, R., Joshi, D., Li, J., & Wang, J. Z. (2008). Image retrieval: Ideas, influences, and trends of the new age. ACM Computing Surveys (Csur), 40(2), 1-60.
http://infolab.stanford.edu/~wangz/project/imsearch/review/JOUR/datta.pdf
[2] Hoi, S. C., & Wu, P. (2011). Sire: a social image retrieval engine. In Proceedings of the 19th ACM international conference on Multimedia (pp. 817-818).
https://ink.library.smu.edu.sg/cgi/viewcontent.cgi?article=3354&context=sis_research
[3] Flickner, M., Sawhney, H., Niblack, W., Ashley, J., Huang, Q., Dom, B., … & Steele, D. (1995). Query by image and video content: The QBIC system. computer, 28(9), 23-32.
http://www1.cs.ucy.ac.cy/~nicolast/courses/cs422/ReadingProjects/qbic.pdf
[4] Portaz, M., Randrianarivo, H., Nivaggioli, A., Maudet, E., Servan, C., & Peyronnet, S. (2019). Image search using multilingual texts: a cross-modal learning approach between image and text Maxime Portaz Qwant Research. arXiv preprint arXiv:1903.11299.
https://arxiv.org/pdf/1903.11299.pdf
[5] https://github.com/QwantResearch/text-image-similarity
![]() Sylvain Peyronnet, concepteur de l’outil d’analyse de backlinks Babbar.
Sylvain Peyronnet, concepteur de l’outil d’analyse de backlinks Babbar.
















5