

La recherche d’images peut revétir plusieurs formes : texte (requête) vers image, image vers image (similarité) ou image vers page web. Dans tous ces cas, des technologies existent aujourd’hui et sont appliquées, souvent avec un bonheur certain, par de nombreux moteurs de recherche. Sylvain Peyronnet, qui a créé le moteur de recherche d’images de Qwant, nous explique dans cette série d’articles ce qui se passe “sous la carrosserie du moteur” et les différents algorithmes utilisés, avec des explications les plus… imagées possible. Ce mois-ci, ce sont les technologies mises en place dans les moteurs permettant d’obtenir des images similaires qui sont étudiées en profondeur.
 Par Sylvain Peyronnet
Par Sylvain Peyronnet
Le mois dernier j’ai évoqué ici-même le concept de moteur de recherche “images”. Nous avons vu qu’il existe plusieurs définitions d’un tel moteur, selon les différents cas d’utilisation.
Au stade actuel de votre lecture, vous savez donc déjà que les moteurs qui sont en production actuellement sont principalement basés sur un mécanisme de recherche dans des textes associés aux images (meta données, texte entourant les images, tags divers et variés), mais qu’il existe aussi des moteurs image-images, c’est-à-dire des moteurs à qui l’on donne en entrée une image (par exemple un chat) et qui vont renvoyer en sortie d’autres images (des chats – pour poursuivre mon exemple). La figure 1 ci-dessous illustre ce mécanisme dans le cadre de l’outil TinEye, qui est principalement utilisé pour la recherche d’images dupliquées sur des sites tiers.

Fig. 1. Recherche d’image similaire à l’homme en VTT, l’outil trouve les duplications de l’image, et propose des images similaires chez un partenaire.
Cette recherche d’images par similarité à une autre image a énormément d’applications en dehors des moteurs de recherche. On a vu plus haut la recherche de copies d’une image, ce qui peut être pratique dans le cadre de la lutte contre le plagiat, mais il existe des applications bien plus importantes.
Nous passerons l’utilisation sécuritaire (recherche de personnes) pour passer à l’utilisation commerciale : la recherche de produits similaires. Explications : imaginez que vous soyez chez un ami pour l’apéro, et vous voyez un fauteuil qui vous plaît, avec une photo et une recherche d’images similaires, à vous tous les fauteuils similaires d’un grand e-commerçant. Si ce scénario d’utilisation vous intéresse, nous vous engageons à lire la référence [1], dans laquelle des ingénieur de Grid Dynamics expliquent comment ils ont réalisé un tel outil (spoiler : ils ont utilisé des réseaux de neurones convolutionnels et une recherche par plus proche voisin). La figure 2 est tiré de leur article : on y voit une recherche de robes similaires à une robe choisie par l’utilisateur.
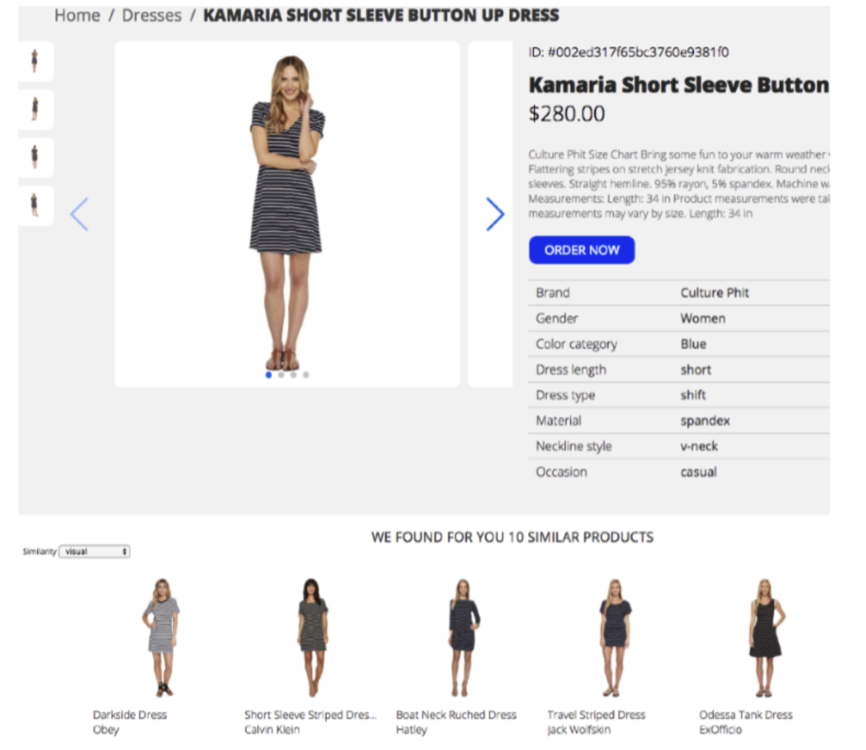
Fig. 2. Recherche de produits par similarité d’images.
La question que nous allons nous poser maintenant, est la suivante : est-ce qu’on peut utiliser la brique de recherche textuelle pour les images et la recherche d’images similaires simultanément pour obtenir de meilleurs résultats sur un moteur de recherche d’images qui soit “full scale”, c’est-à-dire à l’échelle du Web dans son intégralité ?
Mixer recherche d’images via le texte et via la similarité pour un meilleur résultat
La R&D pour arriver à une bonne qualité de résultats de la manière la plus simple possible doit être très pragmatique. Si on fait les comptes, à ce stade on sait déjà trouver des images qui ont été “bien décrites” via des données d’accompagnement et du texte périphérique, et on sait également trouver toutes les images qui ressemblent à une image choisie. Mais on ne sait pas faire un moteur qui indexe et renvoie des images de manière générique (même en l’absence de données textuelles).
Le souci pour un bon moteur d’images est mixte, c’est à la fois l’être humain : on ne peut décemment pas demander à tous les utilisateurs de fournir une image référente pour leur fournir des résultats visuels (et d’ailleurs, comment trouver cette image référente ? C’est le serpent qui se mord la queue). Mais c’est aussi la machine : la plupart des images ne sont pas bien “entourées” de textes et donc les trouver via une requête textuelle est très complexe. Un exemple typique est celui des banques d’images diverses, ou d’archives type flicker où les gens stockent leurs photos au kilomètre, sans y mettre de description texte très complète.
Très rapidement, un moyen de contournement à été mis en place. La notion clé est celle de l’ensemble d’images référentes.
On va constituer un premier index d’images dont les descriptions annexes textuelles sont très fournies. Lorsqu’un utilisateur fait une recherche, on renvoie quelques images de cet index, mais au lieu de les donner directement à l’utilisateur, on va faire une recherche par similarité dans un deuxième index d’images qui ne sont pas nécessairement décrites.
La recherche par similarité étant très efficace, on va avoir au final une meilleure qualité de résultats que si on avait fait une recherche textuelle standard dans un index constitué de toutes les images.
Pour ceux qui veulent simuler le résultat d’un moteur mixte, voici un exemple : imaginez que vous cherchiez des photos de cyclistes habillés en rouge. Si vous tapez “cycliste en rouge sur son vélo”, vous verrez vite que les résultats sont mauvais (voir figure 3).
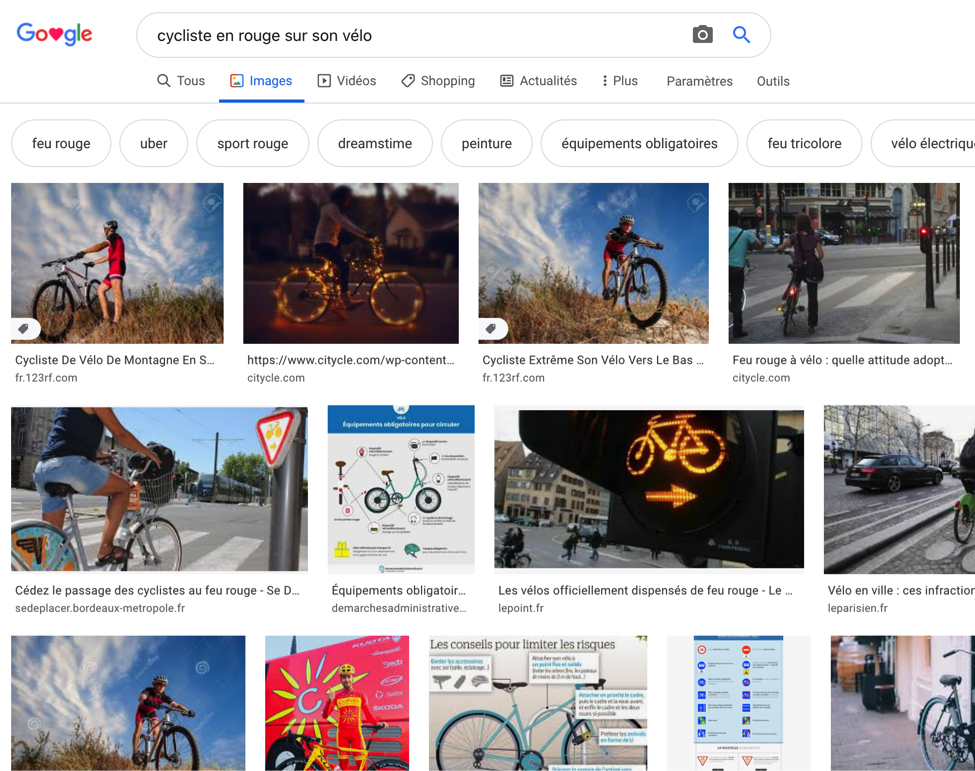
Fig. 3. Requête “cycliste en rouge sur son vélo” dans Google Images.
Il y a cependant des résultats correctes, ce sont ceux qui seront nos images référentes pour une recherche par similarité. Nous faisons cette recherche grâce à la recherche d’images similaires proposé par Google (figure 4).
On voit que les résultats sont plus proches de ce que l’on recherche, alors même qu’on a une seule image référente. Mais tout cela reste perfectible. La question est donc maintenant de savoir si on peut créer un moteur qui “comprend” réellement le contenu des images, et qui peut donc renvoyer des résultats pertinents à des questions qui sont des requêtes descriptives.
Bien entendu, si nous posons la question, c’est que la réponse est positive.
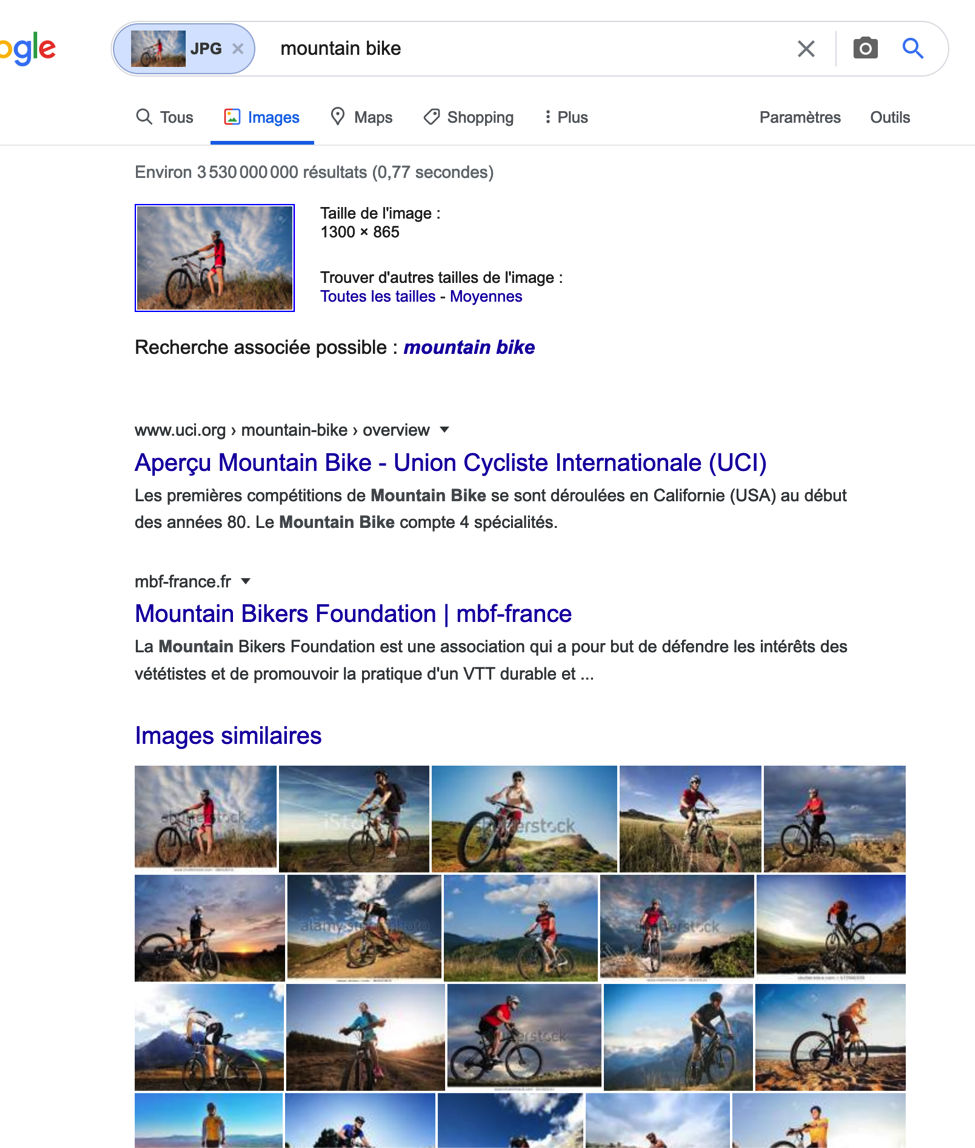
Fig. 4. Recherche d’images similaires.
Utiliser le contenu des images pour les trouver
Les algorithmes et la technologie progressent de concert, et ce qui est possible maintenant est bien plus impressionnant que ce qui l’était hier. Grâce à plusieurs astuces algorithmiques, il est possible de créer un moteur de recherche “cross-modal”, c’est-à-dire un moteur de recherche qui travaille de la même manière sur les images et sur les textes. Alors que j’étais encore directeur scientifique de Qwant, j’ai piloté un projet de recherche sur ce sujet (voir la référence [2]).
Lorsque l’on dit “cross-modal”, on signifie plusieurs choses simultanément. Techniquement, cela veut dire qu’on va mettre en correspondance dans le même espace de recherche (le même index pour le dire de manière intuitive) des concepts très différents. Ces concepts peuvent êtres des images, mais aussi du texte, dans différentes langues. Cela signifie qu’on peut potentiellement avoir un moteur de recherche nativement multilingue, et pour lequel image et texte sont des objets interchangeables.
Pour créer ce type de moteur, on ne va pas faire apparaître magiquement les correspondances entre objets : la cross-modalité se devine grâce à des algorithmes de machine learning qui apprennent de données humaines. S’agissant d’un moteur de recherche images qui soit cross-modal, cette donnée est composée d’images et de descriptions de ces images. La figure 5 est un tel exemple de données d’apprentissage, tiré d’un dataset très connu appelé multi30k.

Fig. 5. Exemple d’images annotées tirées du dataset multi30k.
On voit que les descriptions sont faites dans plusieurs langues, et ne sont pas forcément tout à fait équivalentes (par exemple l’annotation allemande pour la photo du bas évoque la couleur du vêtement de la jeune femme qui fait du roller).
Tout ceci va ensuite être analysé par une chaîne de traitement relativement complexe. La figure 6, tiré de notre article [2] en présente le principe.
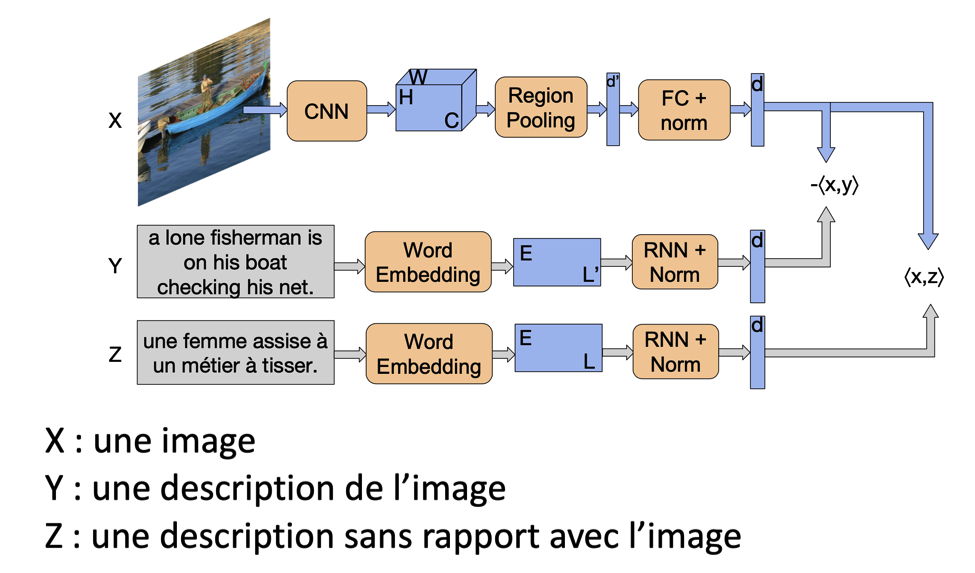
Fig. 6. La chaîne de traitement complète (schéma).
Si on fait abstraction des éléments algorithmiques durs liés au deep learning, le principe est très simple. Chaque image va être analysée par une chaîne de traitement standard à base de réseaux de neurones convolutionnels (c’est la même chose que pour la recherche d’images similaires), visible sur la figure à droite du X.
En même temps, une description de l’image va être utilisé pour mettre en regard le vocabulaire décrivant le contenu et ce contenu (ligne Y), tandis que des textes sans rapport avec le contenu vont servir à voir quels sont les mots qui ne décrivent pas du tout ce contenu. Basiquement, on a créé un ensemble de réseaux de neurones que l’on éduque en expliquant ce qui est dans l’image, et ce qui n’y est pas.
Vous avez sans doute remarqué que les phrases de l’exemple sont pour l’une en anglais, et pour l’autre en français. Cela n’a aucune importance car nous utilisons un encodage simultané de toutes les langues, ce qui permet d’avoir un moteur qui soit nativement multilingue.
Avec toutes ces opérations, il devient très simple de faire un moteur d’images complet. La première opération est de créer l’index : on va prendre toutes les images que le crawler rencontre sur le Web, et on calcule le vecteur qui encode le contenu de l’image, à partir d’un modèle issu du dataset annoté. Si le volume d’annotation est suffisant, on pourra répondre à toutes les requêtes exprimables par des êtres humains.
Lorsqu’un utilisateur saisit une requête, là aussi on va calculer son vecteur, et on renverra les images correspondant aux vecteurs les plus proches (la distance utilisée étant bien connue des lecteurs de Réacteur, il s’agit de la distance angulaire, que les SEOs appellent le cosinus de Salton).
La problématique d’un point de vue industriel est la capacité à faire tout cela très rapidement. A titre d’illustration, le prototype que nous avons mis en place chez Qwant est basé sur 100 millions d’images issues de Flickr, les deux datasets d’entraînement (multi30k et coco, ce dernier venant de chez Google) contiennent environ 150 000 images. La mise en place de l’index a pris plusieurs jours de calcul sur un DGX de NVidia, une machine avec des GPUs V100 (les plus puissants du marché), dont le coût se situe autour de 150 000 dollars.
Une fois la phase d’entraînement terminée, le traitement des images de l’index prend environ 8 secondes pour 800 images. Enfin, quand l’index est constitué, il faut assurer le service, ce qui implique la latence la plus faible possible pour répondre à l’internaute, et pour cela, nous avons choisi d’utiliser des processeurs IPU de chez graphcore, une nouveauté très récente (à la sortie de notre prototype, ils n’étaient pas sur le marché et nous étions alors les premiers – et seuls – utilisateurs). Pour en savoir plus sur ces processeurs et nos travaux, vous pouvez jeter un coup d’oeil aux références [4] et [5].
On peut maintenant se poser la question : dérouler une telle technicité algorithmique et un tel niveau technologique a t-il un sens en terme de qualité de résultats ? La réponse est oui, et pourtant les résultats sont souvent vus comme déroutants par les humains, qui ont perdus l’habitude d’avoir une réponse réelle à leurs requêtes (nous sommes formatés par les moteurs de recherche). A titre d’exemple, la figure 7 présente le résultat direct sur la requête “cycliste en rouge sur son vélo”, nous vous laissons comparer avec les résultats vus plus haut.
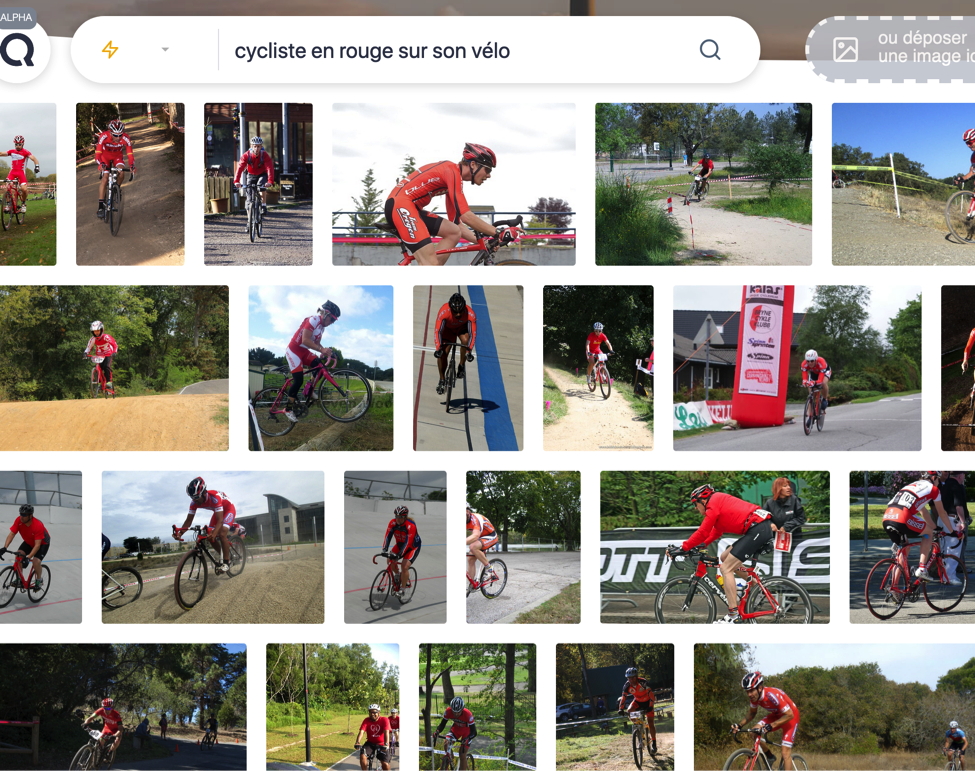
Fig. 7. Le cycliste en rouge pédale tellement vite qu’il est de retour !
Conclusion
La conclusion sera très courte. Aujourd’hui nous avons atteint un niveau algorithmique et technologique qui permet de réellement comprendre les images. Cela ouvre le champ à des nouveaux types d’outils de recherche, plus puissants, plus pertinents également dans les résultats qu’ils fournissent.
Pour le dire plus simplement, aujourd’hui on peut enfin faire des vrais moteurs de recherche “images” !
Références
[1] https://blog.griddynamics.com/expanding-product-search-with-image-similarity/
[2] Portaz, M., Randrianarivo, H., Nivaggioli, A., Maudet, E., Servan, C., & Peyronnet, S. (2019). Image search using multilingual texts: a cross-modal learning approach between image and text Maxime Portaz Qwant Research. arXiv preprint arXiv:1903.11299.
https://arxiv.org/pdf/1903.11299.pdf
[3] Elliott, D., Frank, S., Sima’an, K., & Specia, L. (2016). Multi30k: Multilingual english-german image descriptions. arXiv preprint arXiv:1605.00459.
https://arxiv.org/pdf/1605.00459.pdf
[4] https://www.graphcore.ai/products/ipu
[5] Kacher, I., Portaz, M., Randrianarivo, H., & Peyronnet, S. (2020). Graphcore C2 Card performance for image-based deep learning application: A Report. arXiv preprint arXiv:2002.11670.
https://arxiv.org/pdf/2002.11670.pdf
![]() Sylvain Peyronnet, concepteur de l’outil d’analyse de backlinks Babbar.
Sylvain Peyronnet, concepteur de l’outil d’analyse de backlinks Babbar.












![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-527x297.png)
![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-190x190.png)


5