
 Un des aspects du métier SEO consiste à s’intéresser à l’architecture des sites web. Lorsque vous concevez un cocon sémantique, par exemple, lorsque vous optimisez le maillage d’un site web (les liens internes) ou lorsque vous pensez les menus et les tags en termes de potentiel mot clé, vous touchez à l’ « architecture d’information ». Mais saviez-vous que l’architecture d’information est un métier à part entière, avec ses propres bonnes pratiques, ses stratégies de test et ses livrables ? Une science très sophistiquée aujourd’hui, qui, si elle se couple avec l’intelligence SEO, peut décupler la pertinence d’une refonte ou d’une optimisation de site web. Au cœur de cet article, vous découvrirez au moins 8 points qui devraient vous inciter au couplage de ces deux métiers.
Un des aspects du métier SEO consiste à s’intéresser à l’architecture des sites web. Lorsque vous concevez un cocon sémantique, par exemple, lorsque vous optimisez le maillage d’un site web (les liens internes) ou lorsque vous pensez les menus et les tags en termes de potentiel mot clé, vous touchez à l’ « architecture d’information ». Mais saviez-vous que l’architecture d’information est un métier à part entière, avec ses propres bonnes pratiques, ses stratégies de test et ses livrables ? Une science très sophistiquée aujourd’hui, qui, si elle se couple avec l’intelligence SEO, peut décupler la pertinence d’une refonte ou d’une optimisation de site web. Au cœur de cet article, vous découvrirez au moins 8 points qui devraient vous inciter au couplage de ces deux métiers.
 Un des aspects du métier SEO consiste à s’intéresser à l’architecture des sites web. Lorsque vous concevez un cocon sémantique, par exemple, lorsque vous optimisez le maillage d’un site web (les liens internes) ou lorsque vous pensez les menus et les tags en termes de potentiel mot clé, vous touchez à l’ « architecture d’information ». Mais saviez-vous que l’architecture d’information est un métier à part entière, avec ses propres bonnes pratiques, ses stratégies de test et ses livrables ? Une science très sophistiquée aujourd’hui, qui, si elle se couple avec l’intelligence SEO, peut décupler la pertinence d’une refonte ou d’une optimisation de site web. Au cœur de cet article, vous découvrirez au moins 8 points qui devraient vous inciter au couplage de ces deux métiers.
Un des aspects du métier SEO consiste à s’intéresser à l’architecture des sites web. Lorsque vous concevez un cocon sémantique, par exemple, lorsque vous optimisez le maillage d’un site web (les liens internes) ou lorsque vous pensez les menus et les tags en termes de potentiel mot clé, vous touchez à l’ « architecture d’information ». Mais saviez-vous que l’architecture d’information est un métier à part entière, avec ses propres bonnes pratiques, ses stratégies de test et ses livrables ? Une science très sophistiquée aujourd’hui, qui, si elle se couple avec l’intelligence SEO, peut décupler la pertinence d’une refonte ou d’une optimisation de site web. Au cœur de cet article, vous découvrirez au moins 8 points qui devraient vous inciter au couplage de ces deux métiers.Google revendique explicitement une stratégie qui place l’utilisateur au cœur de ses priorités. Même si les critères d’ergonomie (UX) des sites web ne se retrouvent pas nécessairement pour argent comptant dans les algorithmes, la majorité des experts SEO s’accordent sur l’effet indirect : un site qui génère une bonne expérience utilisateur a beaucoup plus de chances de se retrouver dans le haut du classement.
C’est là qu’intervient l’architecte d’information UX, dont le métier est précisément de s’assurer que la structure de contenu d’un site web est adaptée aux attentes, aux parcours et au vocabulaire de l’utilisateur. L’architecte d’information déploie une série de techniques de conception et de test utilisateur, destinées à déployer un site web intuitif, centré sur les besoins des visiteurs, tout en étant aligné sur les objectifs de l’entreprise.
Dans cet article, nous désirons donc vous parler d’un métier peu connu, essentiel à la réussite des sites web, et surtout très complémentaire au SEO : le métier d’architecte d’information. Mettez un spécialiste SEO aux côtés d’un architecte d’information professionnel et vous obtiendrez un duo gagnant, capable de concevoir un site web aussi performant du point de vue de l’utilisateur que des moteurs de recherche !
L’architecture d’information, c’est l’art d’organiser l’information. Plus précisément l’art d’inventorier, analyser, concevoir, structurer, hiérarchiser et mailler l’information. En anglais, on utilise volontiers le terme « information design », par comparaison avec « graphic design ».
Tout le monde fait (intuitivement) de l’architecture d’information… mais les professionnels, qui maîtrisent les techniques dédiées à la structuration de l’information, se comptent sur les doigts de la main.
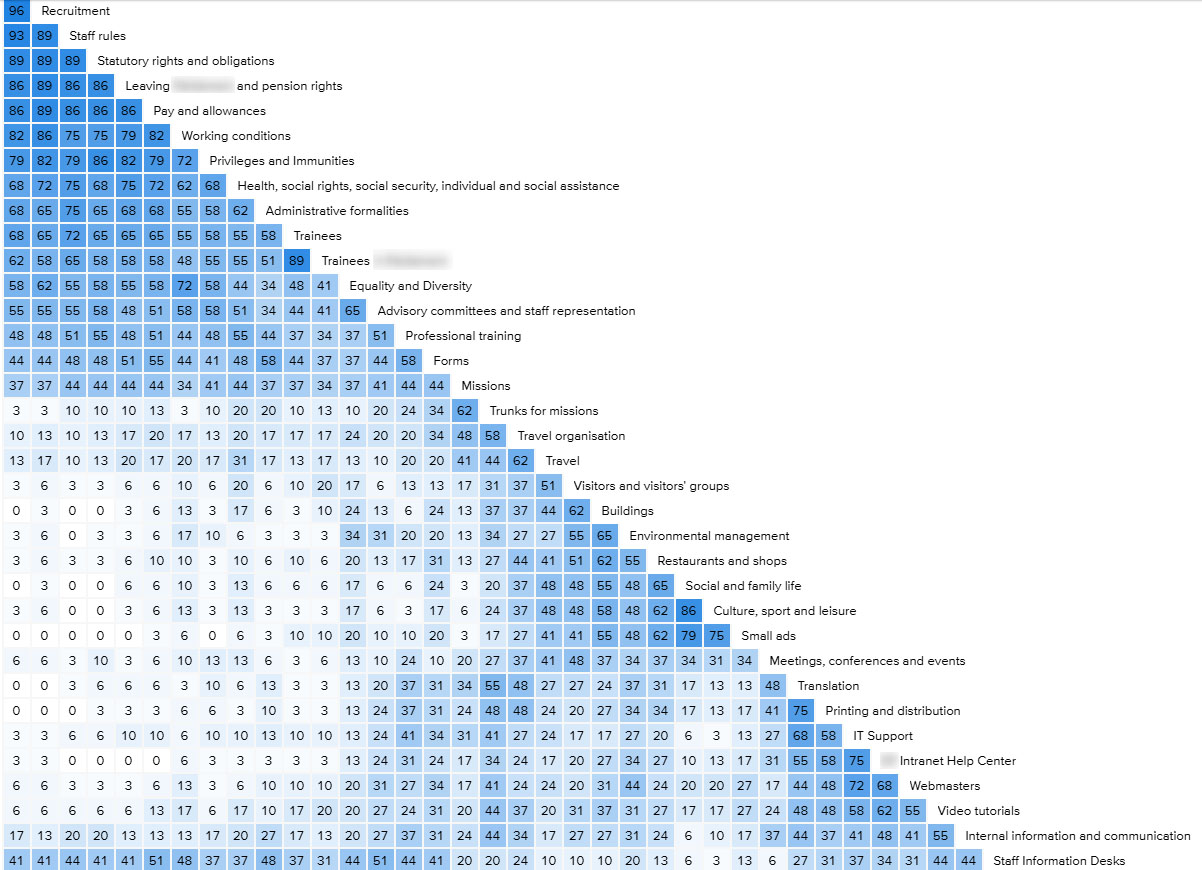 Ci-dessus, la « matrice de similitudes » est une des techniques que nous utilisons pour analyser la « proximité sémantique » entre les différents contenus du site. Cela nous aide à adopter une classification la plus logique possible pour les utilisateurs.
Ci-dessus, la « matrice de similitudes » est une des techniques que nous utilisons pour analyser la « proximité sémantique » entre les différents contenus du site. Cela nous aide à adopter une classification la plus logique possible pour les utilisateurs.
Si vous désirez en savoir plus sur ce métier, lisez donc l’ouvrage de Peter Morville et Louis Rosenfeld : « Architecture de l’information pour le Web » (malheureusement non mis à jour).
L’architecture d’information s’applique aussi bien à la conception de bibliothèques que de tableaux de bord d’aviation, en passant par les applications informatiques. Dans le cas d’un site web, elle se matérialise essentiellement par les livrables suivants : l’inventaire de contenu, l’arborescence (ou site map), les « personas » (profils utilisateurs), les « experience maps » (représentation de scénarios utilisateurs), les menus de navigation, les systèmes de nomenclature et de métadonnées, les « mockups » statiques ou interactifs, les gabarits éditoriaux (modèles de page) et les workflows de maintenance éditoriale.
L’architecte d’information va s’intéresser au découpage de l’information, aux critères de classification et de tri, à la hiérarchie de l’information, aux volumes d’information, à la quantité de choix, à la clarté des libellés, aux relations entre les contenus et à l’évolutivité de l’information. En arrière-fond, l’architecte d’information est centré sur un objectif : faire se rejoindre les attentes des utilisateurs et les objectifs de l’entreprise.
Tout cela sonne un peu abstrait lorsque nous ne sommes pas familiers avec ces concepts, nous sommes bien d’accord. L’architecture de l’information, c’est toute la partie invisible d’un site web, le squelette avant l’habillage. Mais au final, une architecture bien pensée se traduit par des avantages extrêmement concrets : un temps d’accès plus rapide à l’information, moins d’erreurs de parcours, un site plus facile à maintenir et des utilisateurs satisfaits. Sans compter les bénéfices financiers (et écologiques) réalisés grâce à la rationalisation de l’information.
Et le SEO dans tout ça ?
- De la clarté des libellés à la stratégie mots clés, il n’y a qu’un pas.
- Du maillage des contenus à la popularité d’une page, il n’y a qu’un pas.
- De la profondeur de l’arborescence aux crawleurs des robots, il n’y a qu’un pas.
- De l’analyse de redondance à la diminution du contenu dupliqué, il n’y a qu’un pas.
- De la « ROT » analyse à la fraîcheur et à la qualité des contenus, il n’y a qu’un pas.
- De la taxonomie aux métadonnées SEO, il n’y a qu’un pas.
- De la scénarisation des intentions à la pertinence du contenu, il n’y a qu’un pas.
- De la satisfaction des utilisateurs à la satisfaction de Google, il n’y a qu’un pas.
Explorons, au minimum, ces 8 points qui rendent le métier d’architecte d’information redoutablement complémentaire au SEO.
Alors pourquoi une architecture de l’information bien conçue améliore-t-elle le référencement naturel ?
Les libellés : bien plus qu’une question de mots clés !
Comment nommer les rubriques d’un site web ? Quels mots clés choisir pour les tags et catégories ? Comment formuler les titres des pages principales ? Cette question intéresse les SEO, étant donné le poids des mots clés dans ces zones stratégiques, que les moteurs de recherche analysent pour se faire une idée du contenu du site web.
De leur côté, les architectes d’information s’intéressent aussi de très près aux libellés, mais pour d’autres raisons. L’architecte désire vérifier si le vocabulaire utilisé est attractif et compréhensible pour les audiences visées. Il désire s’assurer qu’il n’y a pas d’ambiguïté dans le choix des mots et que ceux-ci vont conduire à un parcours utilisateur prévisible et satisfaisant. Il s’attache à contrôler la cohérence syntaxique des menus (le fait d’utiliser un style grammatical cohérent pour l’ensemble des items d’un menu de navigation, par exemple). Il accorde aussi beaucoup d’importance à la consistance des logiques de classification (parent/enfant, thématique, géographique, temporelle, orientée action, etc.), qui reste son cœur de métier.
Mettez ces deux intelligences côte à côte – une analyse du potentiel mot clé et des tendances mots clés, croisée aux bonnes pratiques d’une architecture orientée utilisateur – et vous obtiendrez un résultat excellent, qui préfigure du succès de votre site web ou de celui de votre client !
Un architecte d’information peu informé sur les enjeux du SEO pourra créer des rubriques inefficaces du point de vue des moteurs de recherche. Si une association pour la petite enfance crée une rubrique « Le lait du nourrisson », elle risque de passer à côté d’une large audience qui cherche « Le lait pour bébé » (c’est un cas vécu).
Inversement, une architecture entièrement créée dans une logique SEO peut présenter d’énormes faiblesses sur le plan de l’expérience utilisateur : le choix de mots clés stratégiques, l’abondance de backlinks ou un code optimisé ne garantissent en rien la qualité de la structuration logique (c’est aussi du vécu).
Bien évidemment, certains SEO sont sensibles à l’UX, et vice-versa. Et c’est une bonne nouvelle. Le but de notre article n’est pas de diviser le monde en deux, mais de réunir les métiers pour une efficacité décuplée. Peu importe ce qui figure sur votre carte de visite, ce qui compte, c’est de marier les bonnes pratiques des différents métiers nécessaires au succès d’un site web.
La chasse aux libellés trop vagues et faiblement révélateurs du contexte peut faire partie de notre travail commun. Prenez les libellés « Magasin », « Outils » et « Lampes », par exemple… De quel type de site web proviennent-ils ? Il pourrait tout aussi bien s’agir d’un magasin de déco que de réparation de voiture, ou même de vente de talons aiguilles !
Remplacez-les par les libellés « Bricolage », « Outils de jardinage » et « Lampes d’extérieur »… les utilisateurs, tout comme les moteurs de recherche, identifieront immédiatement ce contenu comme étant lié à un magasin de bricolage et de jardinage.
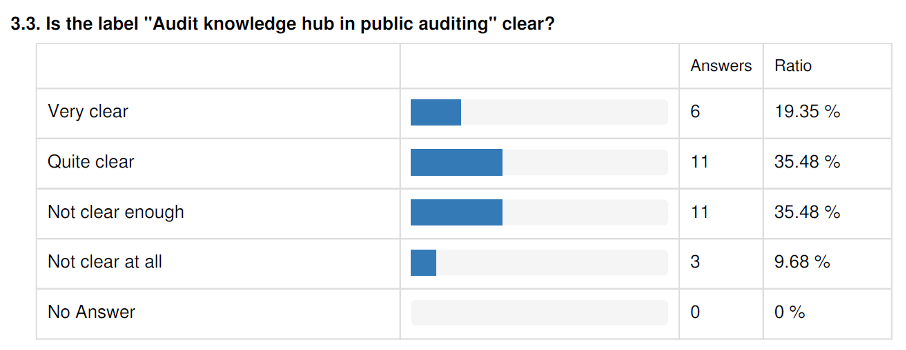
Les libellés sont testés par des utilisateurs. Dans l’exemple ci-dessus, le libellé « Audit Knowledge hub » est recalé . Source : Yellowdolphins.com
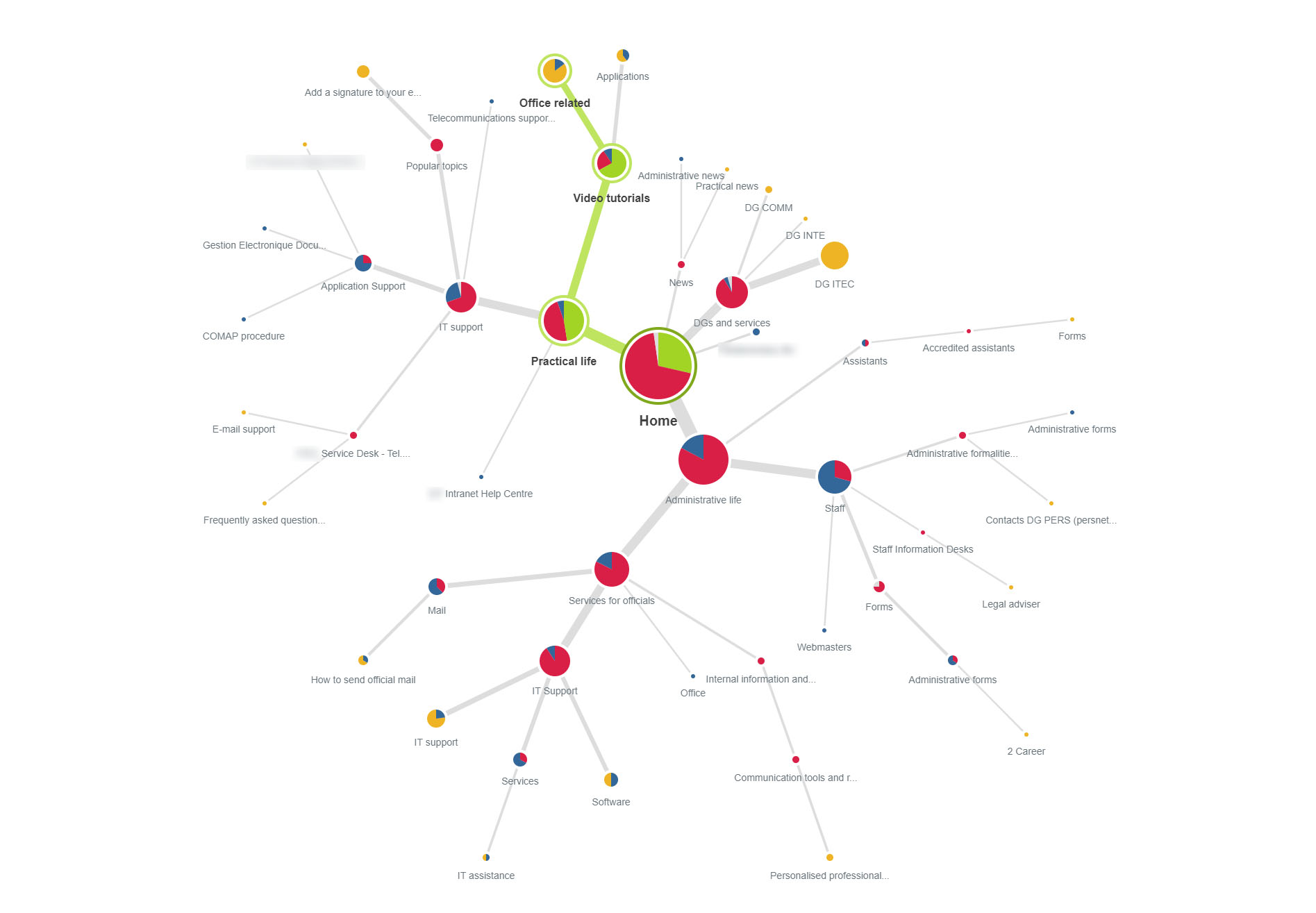
Ci-dessus, une modélisation des difficultés de parcours des utilisateurs, suite à un test d’arborescence. Nous identifions les « nœuds » du site web qui posent des difficultés aux utilisateurs. Nous repérons les impasses, les erreurs d’interprétation, les hésitations. Souvent, en arrière-plan, ce sont les libellés qui induisent les utilisateurs en erreur, lorsqu’ils sont trop génériques, trop imprécis, trop peu intelligibles, trop techniques, trop jargonnant. Source : Yellowdolphins.com
Entretiens, sondages, séances de brainstorming, analyses de trafic, tests utilisateurs : l’architecte de l’information multiplie les outils qui lui permettent de construire une connaissance détaillée de la cible. Ces multiples échanges sont autant d’opportunités pour comprendre, scénariser et prioriser les besoins et les intentions des utilisateurs, mais également pour se familiariser avec leur culture et leur vocabulaire.
En se chargeant de catégoriser et libeller les contenus de sorte que l’utilisateur puisse accéder aux contenus sans ambiguïté, l’architecte d’information apporte de la clarté pour l’utilisateur, mais également pour les robots. En outre, une classification des contenus en rubriques cohérentes viendra soutenir la cohésion sémantique des pages et des rubriques au bénéfice du référencement. L’architecte d’information s’appuie sur des techniques de test éprouvées pour identifier des « clusters » d’information. Traduction : il garantit des groupements de contenu sémantiquement cohérents, qui formeront des cocons précieux du point de vue du référencement.

Des libellés clairs, un bon début ! Source : https://www.francenum.gouv.fr/
Le maillage interne : un levier SEO, mais aussi UX !
Il n’y a que maille qui m’aille, disait la pub ! Idem pour un site web, le système de liens est au centre des enjeux, autant du point de vue SEO que du point de vue UX. Ce n’est pas pour rien qu’on parle de la « toile ».
Les SEO savent depuis longtemps que les liens sont la matière première des moteurs de recherche et, a fortiori, un levier du référencement. Même si l’ère du « pagerank sculpting » est derrière nous, il n’en reste pas moins que les SEO continuent de jouer avec la dose de liens et le ciblage des liens pour canaliser les moteurs de recherche, donner du poids à certaines pages et redistribuer le « jus de notoriété » acquis à force de dur labeur éditorial.
L’architecte d’information, quant à lui, se préoccupe de proposer un maillage qui va permettre à l’utilisateur de réaliser facilement les tâches pour lesquelles il est venu. Les liens internes vont aussi permettre d’assister les utilisateurs perdus ou d’associer des produits commerciaux ou des thématiques corrélées, afin de retenir l’utilisateur un maximum de temps sur le site ou d’encourager le remplissage de son caddie.
Le fil d’Ariane, les tags, les liens associés sont autant de champs qui vont intéresser conjointement SEO et UX, mais pas forcément dans la même perspective.

Le travail de taxonomie (système structuré de tags et de métadonnées utilisé en arrière-plan) va permettre d’automatiser l’affichage de liens au sein des pages de contenu, vers des ressources complémentaires. Ci-dessus, pour un site web dans le domaine de la petite enfance, nous avions mis en place un carrousel automatisé de suggestion d’articles associés à l’article consulté. Source : Yellowdolphins.com
Les parcours utilisateurs pensés par l’architecte d’information ont pour vocation de susciter des expériences riches. Proposer des compléments d’information, des pistes d’exploration ou d’approfondissement en créant un maillage des pages nous permet de générer une expérience utilisateur réussie. Certes, ce maillage influence le référencement, mais il est avant tout guidé par des motifs de qualité de rayonnage et de service à l’utilisateur.
Une fois encore, nous prônons le couplage des métiers. Un maillage purement dicté par des motivations SEO pourra échouer à produire du sens, et dans le pire des cas, pourra générer des incompréhensions de la part des utilisateurs, car il est rarement dans la culture SEO de vérifier l’effet des décisions sur les utilisateurs. À l’inverse, un maillage tout à fait logique et intuitif pour l’utilisateur pourra passer complètement à côté de l’objectif SEO. Par exemple, si vous maillez insuffisamment une page que vous désirez rendre très visible sur les moteurs.
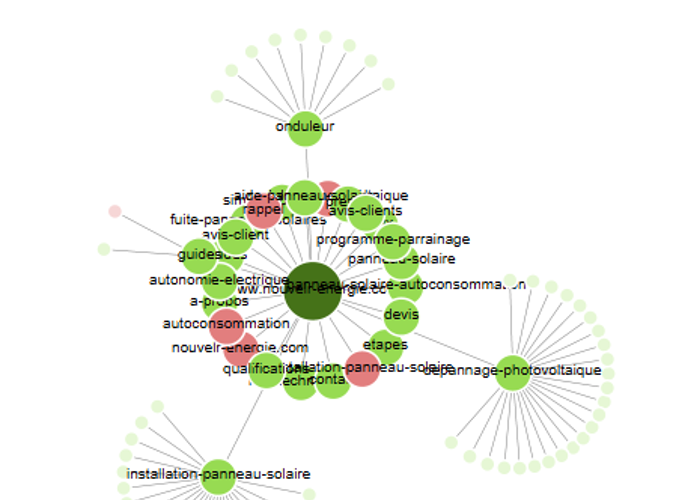
Réfléchir au maillage interne du site, dès la phase de conception. Source : Yellowdolphins.com
Le comble de l’absence de maillage, c’est la page dite « orpheline », qui n’est carrément plus reliée à l’architecture du site… Une page flottante, en apesanteur dans votre système d’information. Les pages orphelines peuvent être le résultat des « rawettes » comme on dit en Belgique, les pages que l’on rajoute par-ci par-là, qui n’appartiennent à aucune catégorie et qui, par conséquent, ne sont plus reliées à l’arborescence. Faute de pouvoir suivre un lien qui mènerait à ces pages, les robots n’en connaissent pas l’existence de sorte qu’elles sont très souvent absentes des pages de résultats (et le Sitemap XML ne comble pas le vide). L’architecte d’information met de l’ordre dans tout cela et s’arrange pour que chaque page retrouve un « parent ». Une bonne architecture n’abandonne personne.
Profondeur du site et indexabilité
Par indexabilité, entendons la capacité pour les robots des moteurs de recherche d’accéder aux pages du site. L’accès aux pages par les robots est la condition sine qua non pour qu’ils puissent en mesurer la pertinence et éventuellement stocker ces pages dans leurs bases de données afin de les présenter sur leurs pages de résultats. Les SEO savent depuis longtemps qu’une page enfouie au plus profond de l’architecture d’un site sera moins facilement accessible qu’une page localisée dans les premiers niveaux de l’arborescence.
L’architecte de l’information se concentre précisément sur le fait de rendre les contenus à valeur ajoutée accessibles en un nombre de clics limités au départ de la page d’accueil. Suppression des pages intermédiaires inutiles, fusion de plusieurs pages en une, élargissement du choix en amont, font partie des techniques utilisées pour y arriver. Très souvent, lorsque nous intervenons sur une arborescence de contenu, nous parvenons à réduire le nombre de niveaux de profondeur de cette architecture.
Dans l’exemple ci-dessous, avant refonte, la majorité des pages se trouvaient enfouies au sixième niveau, comme vous pouvez le constater dans le graphique. Notre travail d’analyse a permis de les remonter dans les trois premiers niveaux et de rationaliser l’arborescence de sorte à obtenir un site sur 5 niveaux maximum. Le bénéfice est double : une meilleure indexabilité par les robots de Google et une réduction du nombre de clics nécessaire pour accéder aux pages d’intérêt pour l’utilisateur !
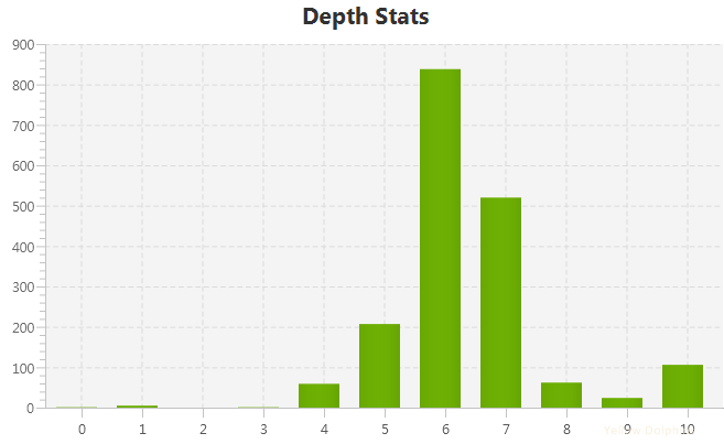
Le site d’une grande institution publique, avant refonte, présentait 10 niveaux. La majorité des URL se situaient au 6e niveau. Dommage pour l’utilisateur et pour le SEO ! Source : Yellowdolphins.com
Redondance et contenu dupliqué
La redondance est un des principaux symptômes d’une mauvaise architecture d’information. C’est clair, la difficulté à classer un contenu dans les « tiroirs » préexistants va nous pousser, très souvent, dans le doute, à dupliquer l’information et à la classer à plusieurs endroits à la fois. Les architectures par audience, tout particulièrement, sont connues pour générer de la redondance. Plus les sites web sont volumineux et plus les contributeurs de contenu sont nombreux, plus le risque de redondance est élevé.

Ci-dessus, sur la droite, les onglets « Personal », « Private », « Business » et « Corporate » sont des entrées correspondant à des audiences, pas forcément évidentes, qui vont générer de la redondance.
Du point de vue SEO, la redondance se traduit par du « contenu dupliqué ». Et comme vous le savez probablement, Google n’aime pas le contenu dupliqué.
Une architecture d’information conçue dans les règles de l’art contiendra très peu de contenu redondant. De plus, le document de gouvernance éditoriale que l’architecte de contenu prévoit proposera un workflow qui vise à éviter la création de contenu redondant (parfois avec des réflexes très simples, mais malheureusement peu appliqués, comme le fait de vérifier si un thème n’a pas déjà été traité avant de se lancer dans la création d’une nouvelle page).
En conclusion, ici encore, l’architecte d’information va travailler en droite ligne avec les objectifs SEO. Et ce, dans la durée !
Cependant, il nous faut quand même ajouter un bémol – et un fameux ! – au regard des pratiques actuelles de la production de contenu. La redondance, dans l’esprit d’un architecte, c’est une redondance de fond. Ce qui revient à dire que deux pages qui parlent de la même chose en des termes différents pourront être considérées comme redondantes par l’architecte d’information, dont la vocation est de rassembler et de consolider tout contenu similaire.
Dans le monde du SEO ou d’un certain marketing de contenu, on n’hésitera pas, à certains moments, à inonder la toile autour d’un sujet, avec des dizaines d’articles parlant finalement de la même chose. La stratégie est de créer de la masse autour d’une thématique et d’aller chercher toute la longue traîne autour d’un sujet (traduisez : couvrir un sujet avec une grande variété de mots clés). C’est une stratégie qui peut s’avérer efficace du point de vue SEO, mais elle est peu écologique, elle a un coût financier élevé en termes d’investissement éditorial et elle finit par noyer les utilisateurs dans des contenus peu consolidés.
Entre quantité et qualité, le débat fait rage aujourd’hui, et on entend de plus en plus parler d’écologie éditoriale, d’autant que toute cette surproduction a un réel impact écologique. Allez-vous consolider votre communication autour d’une architecture épurée, de qualité, ou allez-vous créer de la masse autour de thématiques prédéfinies ? Est-il possible de réussir son SEO sans produire de la masse ? La question est ouverte.
La « ROT » analyse, ou le grand nettoyage des contenus
Dans notre travail d’architecte d’information, nous menons une analyse, connue sous le nom de la « ROT » analyse. ROT signifie « pourri » en anglais et en néerlandais. « Roto » signifie « cassé » en espagnol. Et en français, on est pas loin de la consonance de « raté ». Autrement dit, la ROT analyse va nous mener à identifier le contenu défectueux d’un site web.
Défectueux, le contenu peut l’être de plusieurs manières, et la ROT analyse va se concentrer sur trois aspects : « R » pour « Redundant », « O » pour « Obsolete » et « T » pour « Trivial ». Nous allons donc identifier, puis corriger ou éliminer, le contenu redondant, le contenu obsolète et le contenu trivial. Le bénéfice revient directement à l’utilisateur, mais vous pressentez déjà à quel point il est également lié aux critères SEO.
« R » – La suppression des redondances, nous en avons déjà parlé. Elle a pour effet direct de diminuer le contenu dupliqué. Elle est favorable à votre référencement.
« O » – L’obsolescence, c’est le manque de fraîcheur de vos contenus, le fait qu’ils ne soient plus d’actualité. Et là encore, on touche à un critère de Google. C’est un critère géré subtilement par le moteur de recherche. Certaines thématiques, et certaines requêtes, sont intrinsèquement plus sujettes à l’actualité, et Google rendra ce critère plus prédominant, le cas échéant. Vous bénéficiez parfois d’un effet d’actualité, mais qui ne dure pas nécessairement. Par contre, ce qui est certain, c’est qu’une page qui croupit au fond de votre site web et qui ne donne plus aucun signe de vie, ni éditorialement parlant (mises à jour), ni dans les mentions accordées de l’extérieur (backlinks, commentaires, etc.), une telle page risque de perdre beaucoup de poids aux yeux des visiteurs comme des moteurs de recherche. La ROT analyse nous invite à un nettoyage éditorial salutaire. Elle est très utile, car malheureusement, le nettoyage éditorial est rarement inscrit dans les habitudes et les workflows des entreprises. Le web a fondamentalement tendance à prendre la poussière.
« T » – Les pages triviales sont un peu plus complexes à détecter, car elles demandent une clairvoyance sur la notion de valeur ajoutée éditoriale. Une page triviale est possiblement rédigée dans un bon français très accrocheur et joliment illustrée, mais elle n’apporte pas grand-chose à l’écosystème d’information. Une page triviale, c’est donc une page à faible plus-value éditoriale. Cela ne vous rappelle pas un panda ? NDLR : nous faisons allusion à une série de changements d’algorithmes de Google, surnommée Panda par le monde SEO, et visant à pénaliser les pages de faible qualité. Olivier Duffez, quant à lui, utilise l’expression des « pages zombies » pour se référer à ces pages dépassées ou de faible qualité, qui tirent votre SEO vers le bas (comme le ferait un zombie, sorti d’une tombe, qui agripperait votre cheville pour vous attirer sous terre). Pour en savoir plus sur les critères de fraîcheur et de qualité du contenu, vous pouvez consulter les Quality Rating Guidelines de Google (à télécharger ici pour le guide 2019).
Le grand bénéfice qu’apporte à l’entreprise un architecte d’information, c’est de ne pas se contenter d’une intervention ponctuelle. Si vous nettoyez votre site sans rien changer à vos habitudes, six mois plus tard, c’est retour à la case départ. Vous êtes bons pour repasser la serpillière. C’est la raison pour laquelle nous travaillons beaucoup à la « gouvernance éditoriale ». Dans la foulée d’une refonte, nous accompagnons l’entreprise dans la mise en place de workflows, qui prévoient la suppression, l’archivage, la mise à jour ou l’amélioration d’anciens contenus, de sorte à maintenir la fraîcheur du site web. Ce travail se synthétise, en général, dans un « plan de gouvernance éditorial », mais il peut aussi être évangélisé à travers des formations, des ateliers ou du coaching.
De la taxonomie aux métadonnées SEO
L’architecte d’information partage certains outils avec les SEO. C’est le cas des « aspirateurs de sites web ». L’objectif est de gagner du temps (beaucoup !) dans l’inventaire de l’existant, tant au niveau de la compréhension de l’arborescence que de l’inventaire des métadonnées, formats de fichiers, redirections en place, etc.
Lors de ce travail, nous détectons notamment tous les problèmes liés aux métadonnées qui influencent le SEO, comme la balise TITLE, les balises Hn, les ALT associés aux images, les META Description ainsi que les URL elles-mêmes. Typiquement, les problèmes peuvent être les suivants :
- Métadonnées manquantes (très fréquent pour les ALT et les META descriptions) ;
- Métadonnées redondantes (très fréquent pour les TITLE) ;
- Métadonnées trop courtes ou trop longues.
Ce travail est, la plupart du temps, commun à l’architecte et au spécialiste SEO. Là où l’architecte va apporter une réelle plus-value, c’est en créant une taxonomie consistante, un découpage sémantique non ambigu, qui fait sens pour l’utilisateur et qui va nous guider dans le remplissage et la différenciation des métadonnées. Si votre site web repose sur une classification des contenus fragiles, qui mélange parents, enfants, oncles et tantes, il est clair qu’il va être compliqué de rédiger les étiquettes.
Tout ceci vous paraît abstrait ? Alors, donnons un exemple ! Imaginez que vous vendiez des ordinateurs portables. Ceux-ci, comme vous le savez, ont de multiples caractéristiques, comme la rapidité du processeur, l’autonomie de la batterie, la taille de l’écran, le poids, la connectivité et j’en passe. Si vous ne prévoyez que des fiches produits, vous risquez de vous retrouver avec des métadonnées difficiles à différencier dans l’espace exigu d’un TITLE ou d’une META Description. Du genre : « Ce pentium 12500GH possède une batterie longue autonomie, un écran 17’ et un espace de stockage de 1Tb ». Et pour son voisin de gamme : « Ce pentium 13500GX possède une batterie très longue autonomie, un écran 17’ et un espace de stockage de 1,2Tb ». Par contre, si l’architecture du site prévoit des catégories plus marquées, comme « Batterie haute autonomie : nos meilleurs choix », votre SEO et vos métadonnées seront plus faciles à cibler. Du genre : « Découvrez les portables qui vous offrent la meilleure autonomie de batterie. Jusqu’à 15 heures d’autonomie. Sélection des batteries les plus performantes. »
Le travail de l’architecte va également mettre de l’ordre dans les URL qui composent le site web et qui constituent l’unité de référence pour les moteurs de recherche. Les URL à rallonge, sans cohésion, et en particulier celles qui renferment des mots inintelligibles, sont un cauchemar pour l’utilisateur. Ces URL sont difficiles à mémoriser et à véhiculer. Elles échouent à révéler le contenu de la page. Si ce critère de l’URL représente aujourd’hui un indice de positionnement de faible poids, c’est un critère quand même et votre océan SEO n’est-il pas constitué d’innombrables petites gouttes ?
Scénarisation des intentions et pertinence des contenus
L’intention de l’utilisateur (« user intent ») est au cœur de la démarche de Google. On pourrait pratiquement affirmer que la raison d’être d’un moteur de recherche est d’offrir la réponse la plus pertinente possible à la requête de l’utilisateur (traduisez : son intention de recherche), en fonction du contexte. Or, le travail de l’architecte d’information va être précisément d’explorer, cartographier et scénariser les intentions des utilisateurs, toujours dans l’idée de faire se rejoindre les attentes utilisateurs et l’offre de service ou de contenu, dont dispose l’entreprise.
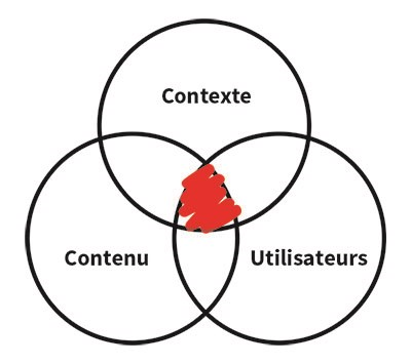
L’architecture de l’information se situe à l’intersection du contexte, du contenu et des utilisateurs. Source : YellowDolphins.com
L’architecture de l’information découle de l’analyse du contenu, des utilisateurs et du contexte. Par « contenu », nous entendons la masse de données disponibles en ligne et hors-ligne, existante ou à venir. Par « utilisateurs », nous comprenons l’audience du site, et en particulier ses besoins et ses comportements en situation de recherche d’information. Enfin, par « contexte », nous faisons référence aux tendances sociétales, aux tendances de marché, aux tendances linguistiques ainsi qu’à la stratégie de l’entreprise, à ses objectifs, ses contraintes, à son environnement technologique, politique, légal, culturel, mais aussi aux ressources humaines et budgétaires.
En tant qu’architectes, ou en tant que SEO, il est important de ne pas considérer uniquement la page prise isolément. Nous la replaçons dans un processus (par exemple, ci-dessous, une commande de pizza). Nous dessinons des « experience maps », qui représentent le parcours de l’utilisateur pour différents scénarios que nous considérons comme importants.
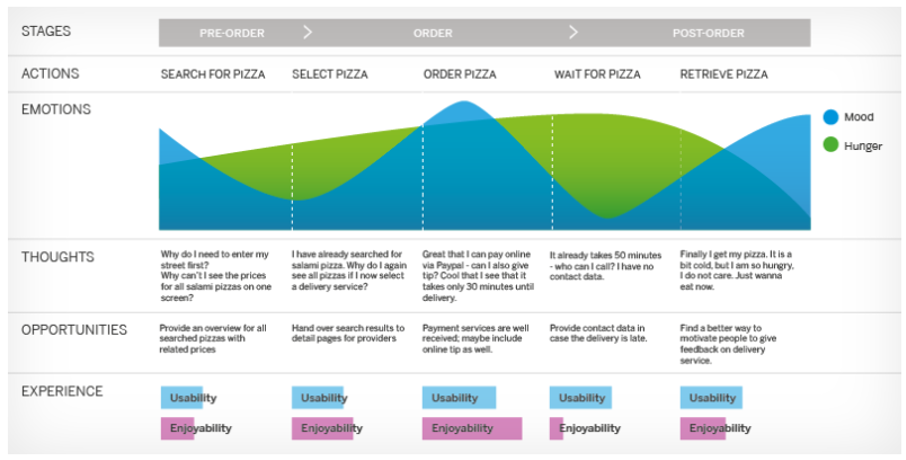
Source : https://experience.sap.com/skillup/experience-mapping/
L’investissement SEO va pouvoir se faire soit tout à fait en amont du processus (par exemple, on va référencer les rayons de produits et les fiches produits, et non les étapes du caddie, cela va de soi), soit nous allons pouvoir référencer différentes étapes de l’expérience d’un contenu ou d’un produit, pour attirer un trafic d’une technicité ou d’une maturité variable.
Typiquement :
- Une recherche centrée sur un besoin (exemple : « comment améliorer l’endormissement d’un bébé ») ;
- Une recherche centrée sur un produit (exemple : « lampes veilleuses » ou « berceuses ») ;
- Une recherche centrée sur une caractéristique de produit (exemple : « lampe veilleuse avec musique berceuse intégrée » ou « lampe veilleuse bleue ») ;
- Une recherche centrée sur un produit spécifique (exemple : « lampe berceuse Chicco First Dreams ») ;
- Une recherche centrée sur l’utilisation d’un produit (exemple : « comment paramétrer la Chicco First Dreams ? »).
Mais le même raisonnement est valable pour des matières éditoriales, institutionnelles, B2B, etc. Et c’est là qu’une architecture ne s’improvise pas. Elle demande de mettre bout à bout la « business analyse » et l’analyse des « besoins utilisateurs », lesquelles ne seront pas « sucées du pouce », mais reposeront sur des interviews, des sondages, des statistiques et des tests consistants. Le SEO pourra alors être construit sur une pyramide des besoins solide, correspondant à la réalité de l’offre et de la demande.
Une fois encore, nous voulons éviter tout cliché : il existe, bien sûr, des experts SEO (les meilleurs, probablement) qui ont déjà un pied, de fait, dans la business analyse. Mais restons critiques, c’est loin d’être toujours le cas. Et, à un certain stade, il est difficile de tout maîtriser. L’architecte d’information privilégie une vue globale et transversale, là où le SEO sera capable de développer une expérience pointue du code, des territoires mots clés et de la chasse aux backlinks. Travaillons donc ensemble ?
Satisfaction des utilisateurs
Imaginez qu’à chaque fois qu’un utilisateur lance une recherche sur Google, il atterrisse sur votre site, regarde votre offre de contenu, n’y comprenne rien, ou ne trouve pas d’emblée ce qu’il cherche, et reparte pour lancer une nouvelle recherche sur la page d’accueil du moteur… Quel signal est donné aux robots ? Un signal négatif, s’il est systématique : le signal que votre site n’a pas donné satisfaction à l’utilisateur, lequel, non assouvi, poursuit sa recherche ailleurs. À la longue, il est peu probable que les moteurs continuent à proposer vos pages sur ces requêtes.
Une bonne architecture d’information va considérablement réduire ce scénario défavorable, pour différentes raisons :
- Le contenu colle à ce qui est annoncé ;
- Le contenu est parlant (des libellés et un vocabulaire éprouvés) ;
- Le contenu est à jour (non obsolète, voir plus haut) ;
- Le contenu est consistant (non trivial, voire plus haut) ;
- Le contenu répond à tous les aspects de la question (consolidé, non redondant) ;
- Le contenu, surtout, est le point de départ d’une expérience réussie.
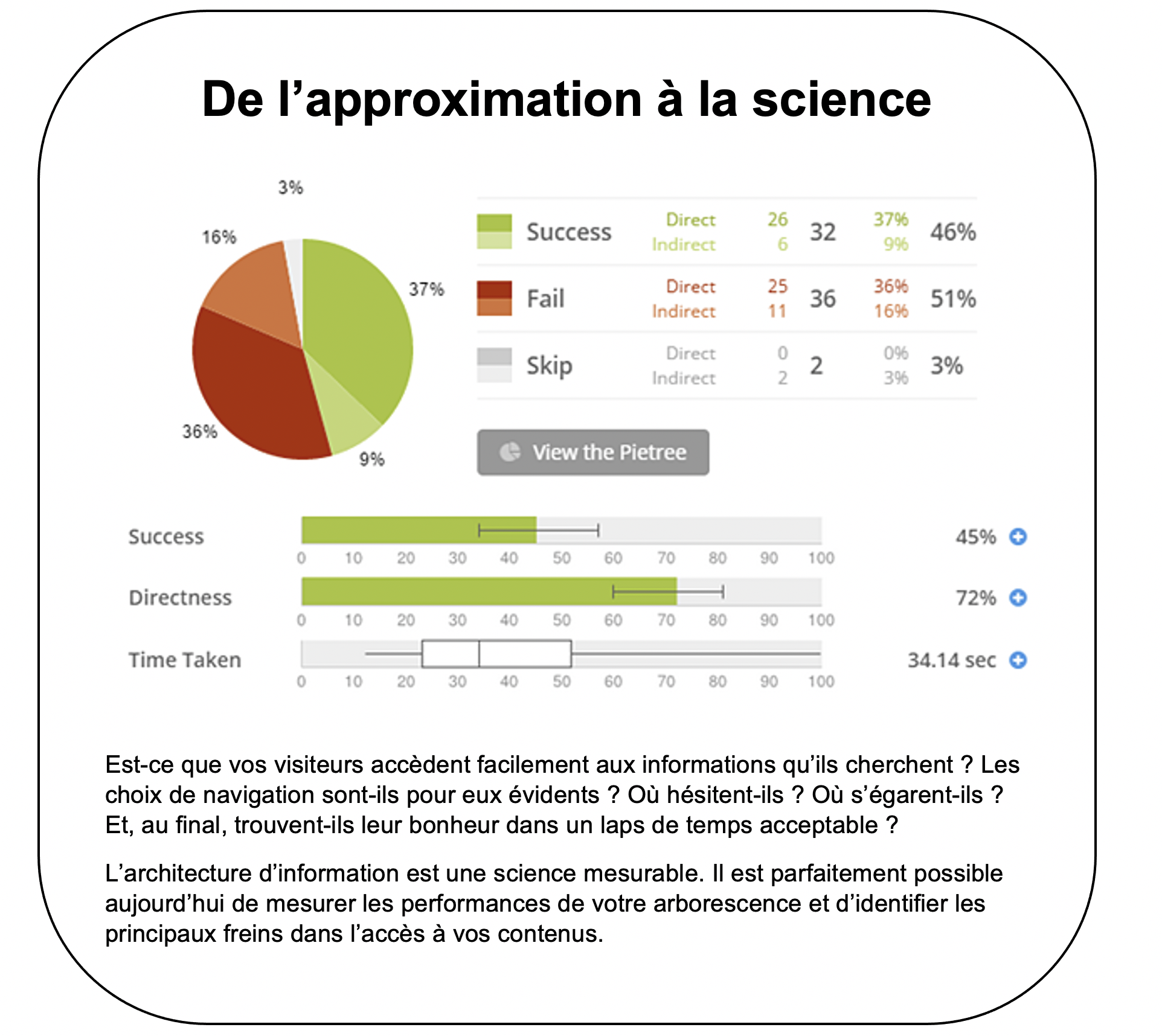
Cette expérience réussie n’est pas le fruit du hasard. Elle repose sur toute une batterie de tests utilisateurs, qui sont, au fil du temps, de plus en plus affinés. Les premiers tests peuvent nous permettre d’atteindre un taux de succès de 70%, par exemple. Après deux ou trois tests d’affinement, on peut arriver à un taux de succès de 90 à 95%. Soyons clairs, il reste toujours un peu de déchet. On reste des humains
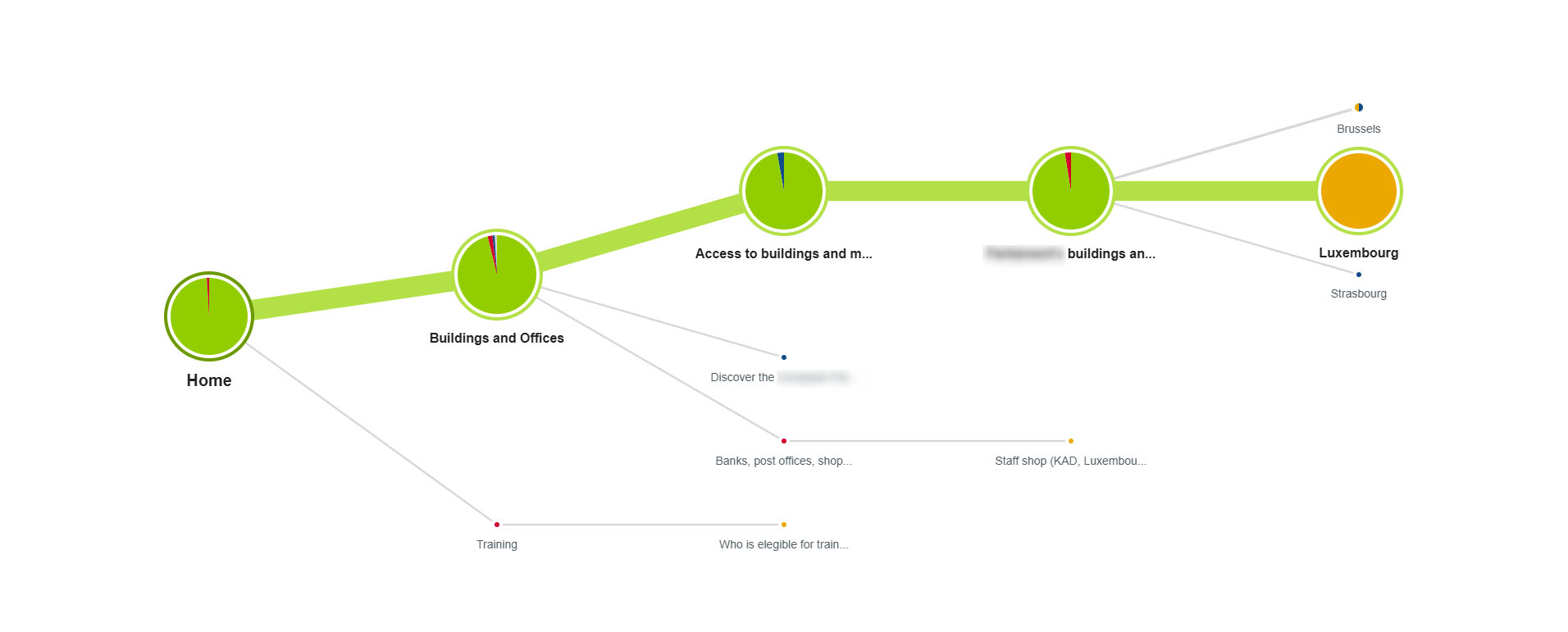
Exemple de parcours avec très peu d’hésitation. Les utilisateurs cherchaient le plan d’accès aux bureaux de Luxembourg d’une grande institution internationale. Dans l’architecture de l’ancien site web, l’expérience était beaucoup plus chaotique. À présent, peu d’utilisateurs s’égarent. Source : yellowdolphins.com
Nous n’avons pas la prétention d’avoir répondu à toutes les questions et traité tous les sujets, mais nous espérons, à travers cet article, vous avoir convaincus de la technicité du métier d’architecte d’information et du gain considérable à coupler le SEO à l’architecte. Plus que jamais, SEO, UX, architecture et marketing de contenu sont des matières qui demandent une alchimie. Nous encourageons le rapprochement des métiers.
Vous désirez aller plus loin ? Consultez notre dossier complet sur l’architecture de l’information et la refonte de sites web. Ou contactez-nous directement, nous aimons les questions 🙂

![]() Isabelle Canivet et Jean-Marc Hardy, experts en architecture de l’information, Yellow Dolphins
Isabelle Canivet et Jean-Marc Hardy, experts en architecture de l’information, Yellow Dolphins














![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-527x297.png)
![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-190x190.png)
5
5
4.5