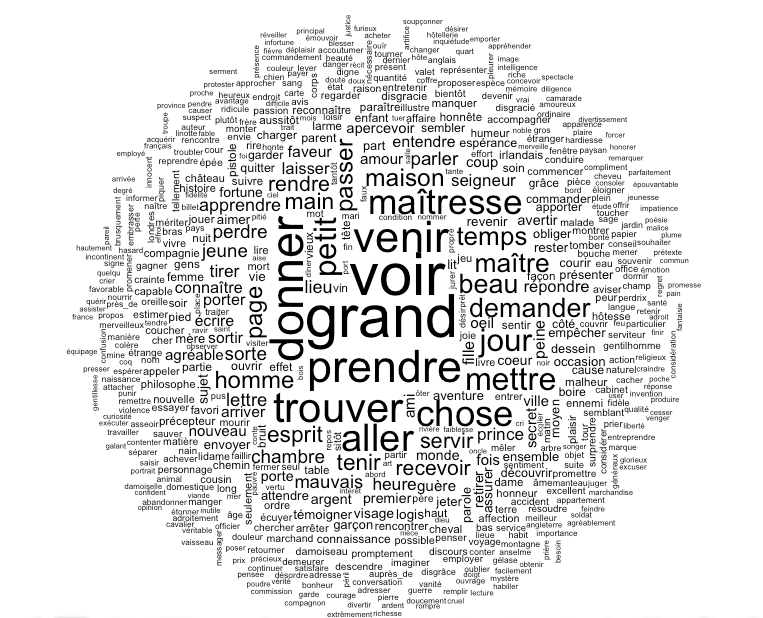
On n’optimise plus en 2016 un contenu textuel pour une requête unique lorsqu’on désire être visible sur Google, Bing et consorts. Les algorithmes des moteurs de recherche prennent en compte la sémantique et il est important, lors de la rédaction, de s’appuyer sur un champ lexical étendu et donc sur des mots clés ou termes secondaires, complémentaires de la requête visée au départ. Voici donc une méthodologie, basée sur l’analyse lexicale et les co-occurrences, pour vous aider dans cette voie…

 Par Guillaume et Sylvain Peyronnet
Par Guillaume et Sylvain Peyronnet
Depuis maintenant plusieurs années (probablement depuis 2012 pour être exact), Google utilise des algorithmes de reformulation de requête pour mieux comprendre ce que les internautes expriment maladroitement, ne permettant pas au moteur de trouver de bons résultats directement.
Avec ces techniques de reformulation, la requête qui est tapée par l’utilisateur du moteur n’est pas forcément celle que ce dernier va utiliser pour construire les SERP. La question qui se pose alors pour les SEO est de savoir s’il est possible d’anticiper les reformulations pour travailler sur des mots-clés complémentaires pour maximiser ses positions, même sur des requêtes qui seront potentiellement reformulées.
Dans cet article, nous vous proposons un algorithme pour trouver ces mots-clés complémentaires, en se basant sur la notion de co-occurrence, que l’on retrouve par exemple au cœur du brevet [1] que Bill Slawski avait appelé le brevet « Hummingbird » à l’époque.
La nécessité de la reformulation pour le moteur de recherche
Le médium entre l’internaute et le moteur est la boite de dialogue (le formulaire de recherche) qui permet de saisir la requête. Malheureusement, de très nombreux problèmes se posent concernant ce « dialogue » : fautes d’orthographe, mots ambigüs, utilisation d’un vocabulaire inhabituel (« pince crocodile » au lieu de « pince multifonctions » par exemple), etc.
Pour lutter contre ces problèmes liés à compréhension de la requête, le moteur utilise des algorithmes spécifiques de reformulation (ou extension). Parmi les méthodes de reformulation, on trouve celles basées sur la notion de co-occurrence, qui est celle qui va nous être utile dans le contexte de cet article.
En utilisant les co-occurrences, le moteur va pouvoir préciser le sens d’une requête en lui rajoutant des mots-clés complémentaires, voire en substituant ces mots-clés complémentaires à certaines parties de la requête.
Intuitivement, la notion de co-occurrence est assez simple : on dira que deux mots sont co-occurrents si ils apparaissent ensemble dans un même bloc sémantique. Il est d’ailleurs très important de noter que la définition même de champ lexical ou thématique est basée sur la notion de co-occurrence : des mots d’un même champ lexical sont souvent co-occurrents et des mots souvent co-occurrents sont souvent présents dans un même champ lexical. On repère également la notion de décalage de champ lexical au fait qu’un mot devient moins co-occurrent aux autres mots d’un champ lexical, signifiant ainsi que son usage est en cours de changement.
Le terme plus scientifique pour la co-occurrence est « mesure d’association », il existe plusieurs types de mesures, dont la figure 1 nous montre quatre exemples.
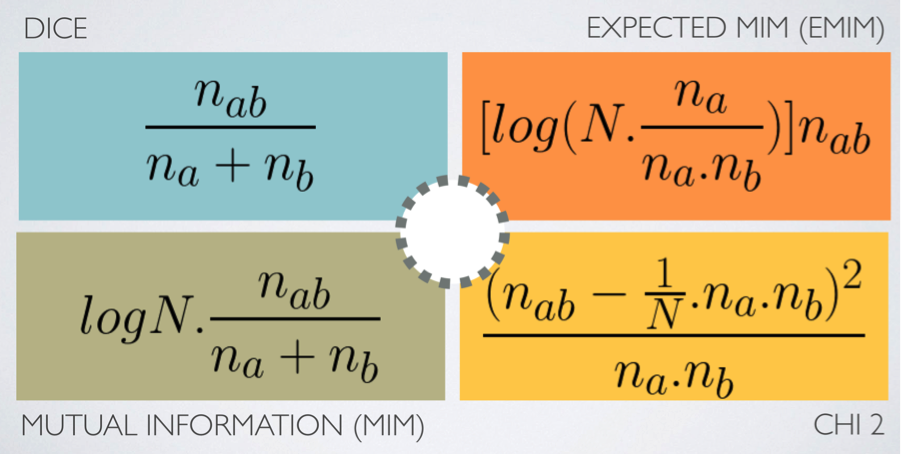
Fig. 1. 4 types de mesure d’association.
Que nous disent ces formules cabalistiques ? La mesure de Dice est la plus intuitive : elle nous explique que l’association entre deux termes a et b est essentiellement la proportion de document qui contiennent a et b ensemble par rapport à ceux qui contiennent a ou b (ou les deux, bien sûr).
![]() Guillaume Peyronnet est gérant de Nalrem Médias.
Guillaume Peyronnet est gérant de Nalrem Médias.
Sylvain Peyronnet est co-fondateur et responsable des ix-labs, un laboratoire de recherche privé.
Ensemble, ils font des formations, pour en savoir plus : http://www.peyronnet.eu/blog/












![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-527x297.png)
![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-190x190.png)