
 Après avoir exploré la configuration de l’outil Screaming Frog le mois dernier, faisons place ce mois-ci à deux problématiques importantes : l’analyse de la structure du site (profondeur de crawl, URL, codes renvoyés, etc.) et détection du contenu dupliqué, avec de nouvelles fonctionnalités très intéressantes qui ont dernièrement fait leur apparition sur le logiciel dans ce domaine.
Après avoir exploré la configuration de l’outil Screaming Frog le mois dernier, faisons place ce mois-ci à deux problématiques importantes : l’analyse de la structure du site (profondeur de crawl, URL, codes renvoyés, etc.) et détection du contenu dupliqué, avec de nouvelles fonctionnalités très intéressantes qui ont dernièrement fait leur apparition sur le logiciel dans ce domaine.
Dans notre article précédent, nous avons vu comment bien configurer plusieurs paramètres avant de lancer son crawl. L’outil Screaming Frog est en effet capable de récupérer de nombreuses données liées au SEO (balises title, meta, hreflang, canonical, etc.), mais également d’extraire un certain nombre d’éléments au sein des pages (via les expression régulières, le langage Xpath,…), sans oublier les connexions à des API externes (Google Search Console, Analytics, qui permettent d’avoir des données pour chaque URL.
Nous verrons dans cet articles quelques astuces afin de bien interpréter les données restituées par l’outil, ainsi que des fonctionnalités permettant de dessiner la stratégie SEO à adopter, en fonction des résultats d’un crawl.
Structure du site
Alors que l’onglet « Overview » situé dans la colonne de droite du crawler permet de naviguer simplement entre les différents indicateurs SEO avec une vue d’ensemble pour chacun d’entre eux (chaque KPI correspondant à un onglet), l’onglet « Site structure » permet d’avoir un aperçu global de la profondeur de chaque URL, depuis la page de départ. Dans l’exemple ci-dessous, le graphique nous indique que la grande majeure partie des URL se trouvent au-delà d’une profondeur de niveau 10, soit plus de 10 clics depuis la page d’accueil pour accéder à plus de 100.000 URL.
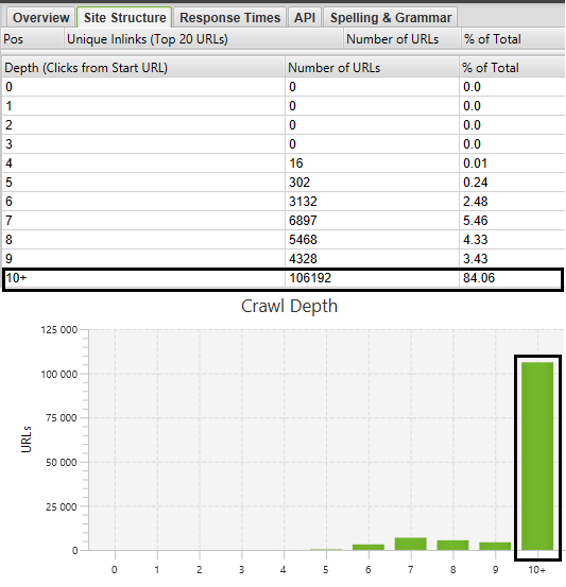
Figure 1 – Profondeur des URL
Cela peut d’entrée donner un indicateur sur une problématique de maillage avec un ensemble de contenus accessibles via de la pagination importante par exemple, mais pas uniquement.
Ce phénomène peut également être provoqué par un « spider trap », à savoir une suite d’URL dans lesquelles le crawler s’engouffrerait après une mauvaise configuration de liens, couplée à une réécriture d’URL incomplète (ex : structures de répertoires indéfiniment profonde comme http://example.com/bar/foo/bar/foo/bar/foo/bar/…).
Une URL profonde n’est d’ailleurs pas systématiquement un mauvais point : c’est le contexte qui prime, en complément de son potentiel SEO. Une page profonde ciblant des requêtes de longue traîne, mais recevant des liens bien contextualisés peut être efficace.
Par ailleurs, il faut garder à l’esprit que l’onglet « Site structure » reporte la profondeur pour toutes les typologies d’URL (page web, fichiers css, JS, etc.). Il est donc important de bien regarder les URL concernées par une profondeur élevée : il se peut que les URL les plus profondes soient relatives à des images (éléments en fin de chaîne, ne proposant pas de liens sortants), comme dans l’exemple ci-dessous :
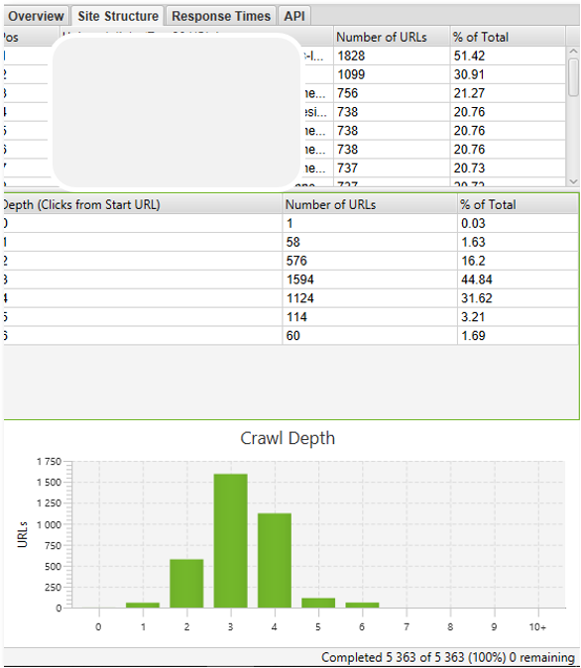
Figure 2- URL profondes relatives à des fichiers images
Une conclusion trop hâtive pourrait mener à l’affirmation erronée « Ce site a un problème de maillage, car près d’1/3 des pages sont au-delà de la profondeur 3. Les URL sont trop profondes et seront moins crawlées par Google, et se positionneront mal. »
Une URL profonde peut se positionner : ce qui fera la différence, c’est le nombre de liens vers cet dernière, et le contexte dans lequel elle reçoit ces liens. On voit d’ailleurs sur de nombreux sites e-commerce des URL issues de la navigation à facettes (et donc parfois profondes) générer une part importante du trafic. En l’occurrence dans l’exemple qui précède, la majeure partie des URL en profondeur 4 ne sont que des images, ce qui n’est pas un problème en soit.
Analyse sur un groupe d’URL
Il est d’ailleurs possible de supprimer une partie des URL pour avoir une vision plus claire de la profondeur de ses URL, en excluant les fichiers JS, CSS ou images. Pour cela (en ayant préalablement configuré son crawler en mode « Base de données »), il vous suffit de dupliquer votre crawl en vous rendant dans la liste des crawls (File > Crawls).
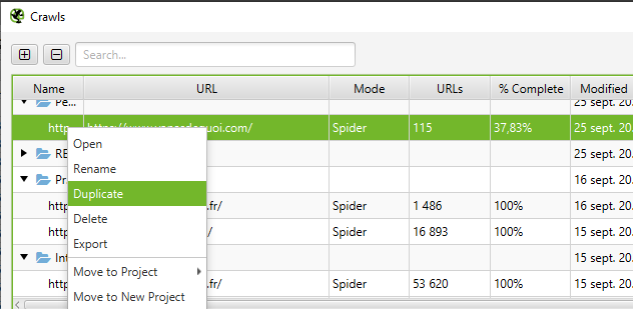
Après avoir ouvert votre crawl dupliqué, il ne restera qu’à plus qu’à supprimer les URL que vous souhaitez exclure de votre analyse, en les sélectionnant :
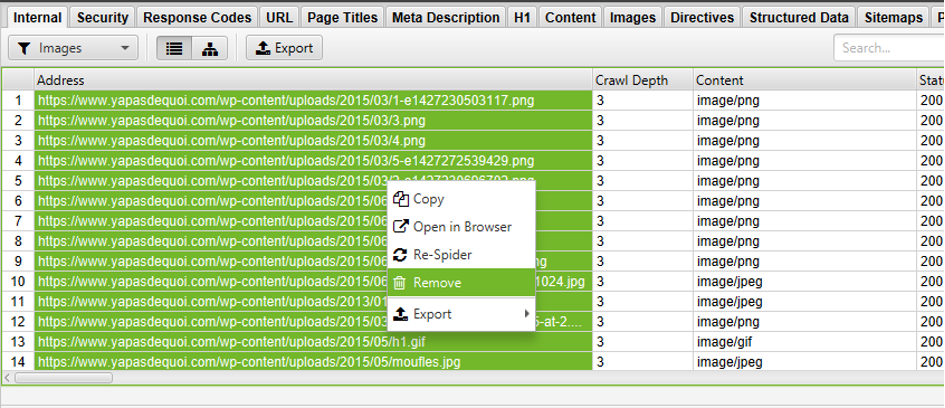
Figure 3 – suppression d’URL crawlées pour une analyse spécifique
Cette méthode est d’ailleurs utile pour analyser un segment spécifique d’un site (répertoire ou groupe de pages). En ayant une vision plus précise des problématiques par type de page, il est intéressant de s’attarder sur les problématiques d’URL.
Problématiques d’URL
Paramètres d’URL
Les paramètres d’URL sont souvent la source de contenu dupliqué, mais également de l’indexation de pages non pertinentes (ex : URL de tri). Via l’onglet « URL » de l’outil, en filtrant les URL contenant des paramètres, on pourra mettre en avant facilement ces URL et leur impact sur le SEO.
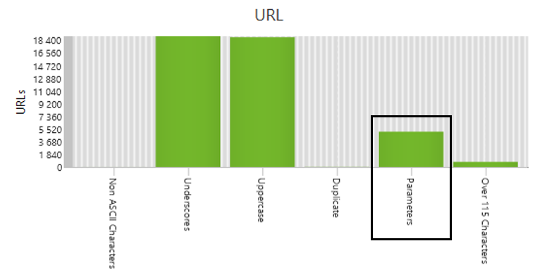
Figure 4 – Structure des URL
Dans la sélection d’URL avec des paramètres ci-dessous, nous constatons la présence d’URL modifiant l’affichage d’une page via un paramètre de tri ( ?reviewsSort=byDate):
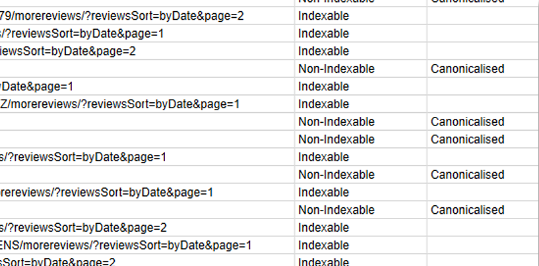
Figure 5 – URL contenant des paramètres
Il s’agit d’URL modifiant l’affichage des avis laissés par les internautes sur une fiche produit d’un site e-commerce. Ces URL peuvent être source de duplication, et ne présentent pas d’intérêt dans le cadre de la stratégie SEO. Il conviendra donc de limiter l’accès aux crawlers sur ces pages afin de :
- Réduire la perte de popularité envoyé vers ces pages
- Améliorer la qualité des pages dans l’index.
Une adaptation de la structure des liens, couplée à la mise en place d’une directive dans le fichier robots.txt corrigera le problème (si besoin avec une phase de désindexation préalable du groupe d’URL concernées).
Nous remarquons d’ailleurs dans la capture ci-dessus que certaines URL sont indiquées comme n’étant pas indexables (URL faisant référence à une URL canonique). Ça n’est pas parce que l’outil renvoie « Canonicalised » que c’est une bonne chose. En effet, Google traite de façon beaucoup plus fine les URL canoniques (comme les redirections 301 d’ailleurs), et si les pages ne sont pas tout à fait équivalentes en terme de contenu, il ne tiendra tout simplement pas compte de la balise Canonical.
Il n’est pas rare de voir des URL paginées comme par exemple « /mes-produits?p=1 », « /mes-produits?p=2 », … mentionnant la première URL de la série (« /mes-produits ») comme étant l’URL canonique. Cette pratique n’est pas recommandée dans la mesure où les produits présentés d’une page à l’autres ne sont pas les mêmes, la balise title ne suffit pas à tromper Google. Si l’on regarde l’URL suivante : https://www.rosnysousbois.fr/annuaires/page/3/ , elle contient une balise Canonical vers la première page de la série :

Figure 6 – balise Canonical erronée
Dans les pages de résultats de Google, nous constatons bien que la balise Canonical n’est pas prise en compte et que les pages paginées remontent dans l’index (ce qui ne correspond pas à l’effet souhaité) :
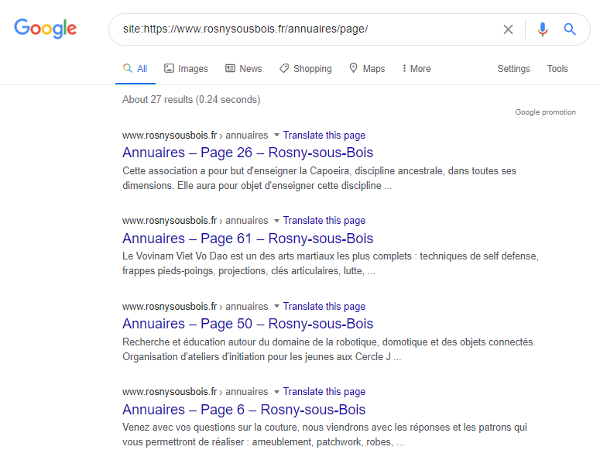
Figure 7 – Pages remontant dans les résultats malgré une balise Canonical
Les Canonical remontées par Screaming Frog sont indiquées comme « Non-indexable », et nous voyons bien que la « Canonical » ne fait pas tout, il ne faut pas prendre tout ce que dit l’outil pour argent comptant, et vérifier la prise en compte des directives par les algorithmes de Google.
Codes réponses
Redirections 301
Dans l’onglet « Responses codes », nous avons un aperçu des statuts HTTP retournés à Screaming Frog lors du crawl. Comme pour la structure du site, ils concernent l’ensemble des URL. Si vous avez de nombreuses images, cela peut vous induire en erreur sur l’interprétation des données relatives aux codes réponses : la duplication du crawl, refiltrée sur les pages HTML uniquement pourra une nouvelle fois vous permettre d’y voir plus clair.
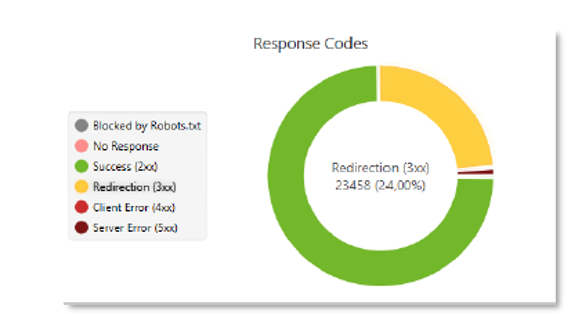
Figure 8 – codes réponse suite à un crawl
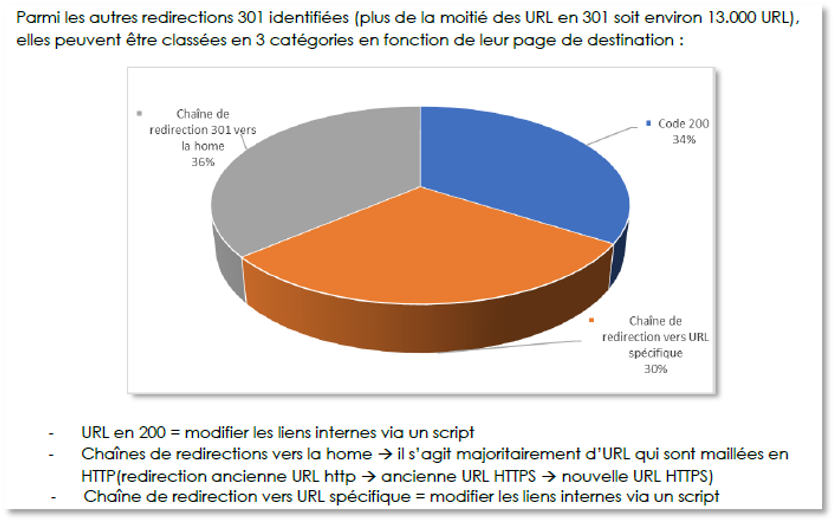
Dans cet exemple, nous constatons près d’1/4 de redirections 301 sur la totalité des URL visitées par l’outil. Les bonnes questions à se poser à propos de ces redirections sont :
- Y-a-t-il des similarités entre ces URL redirigées ?
- Quelle est la source de ces redirections ?
Il faut garder à l’esprit que si Screaming Frog navigue de liens en liens, il visite également les URL trouvées dans des balises HTML de type <link> : canonical, hreflang, amphtml, etc.
C’est en regroupant les redirections par type que des optimisations efficaces pourront être mises en place. Après avoir qualifié l’ensemble de ces URL (dans un export Excel/Google Sheets), voici ce qu’il en ressort :
Pour avoir une meilleure compréhension des redirections, il aura fallu au préalable permettre à l’outil de suivre ces dernières lors de la phase de paramétrage (Menu « Configuration » > « Spider », puis onglet « Advanced ») :
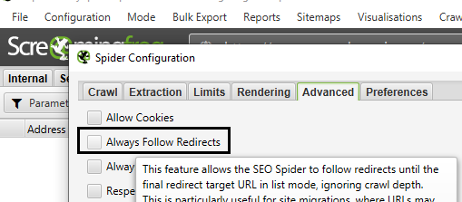
Figure 9 – Suivi des redirections par le crawler
Notez par ailleurs qu’en cas de suite de plusieurs redirections, la génération d’un export au format .csv ou .xlsx vous sera d’une grande aide pour mieux comprendre le chaînage entre plusieurs 301 :
Bien que Google soit en théorie capable de suivre une suite de 5 redirections, nous pouvons encore constater que la prise en compte de ces chaînes de 301/302 est encore extrêmement longue, et pas toujours effective.
Erreurs 404
Il arrive que certains sites renvoient des softs 404, c’est-à-dire affichent une page comme introuvable, mais en renvoyant en statut HTTP 200, ce qui fera que la page d’erreur sera indexée. Un crawl sans aucune erreur 404 est relativement rare :
Figure 10 – Résultat d’un crawl sans aucune erreur. Ça arrive 🙂
Voici le cas d’un site qui renvoie à tort un code 200 sur une URL de type 404 :
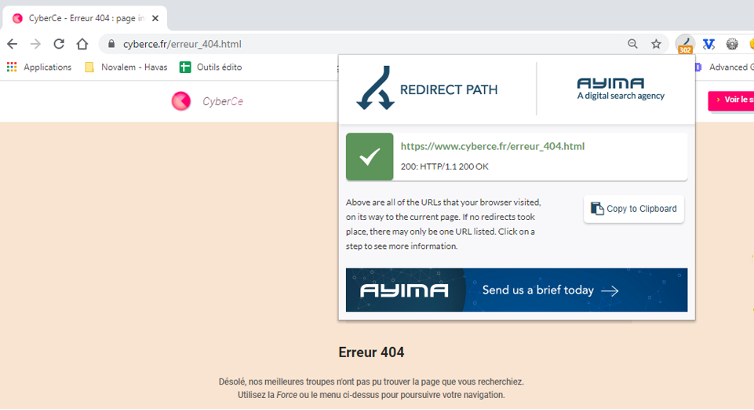
Dans le cas présent, il est recommandé de tester une URL inexistante sur le domaine crawlé (ex : https://www.monsite.com/qiusdkjhqis), pour s’assurer que le serveur renvoie correctement un code d’erreur 404.
Source d’un lien cassé
Dans le cas où certains liens seraient corrompus sur le site (lien erroné qui génère une page d’erreur 404), il est utile de pouvoir remonter l’origine de ces liens vers des 404, mais cela peut vite devenir un calvaire. En effet, il se peut que ces mêmes liens soient générés à partir d’une page dont ne connait pas l’origine. Il faudra dans ce cas reconstituer tout le chemin vers la page en 404 via le volet « Inlinks » des URL concernées :
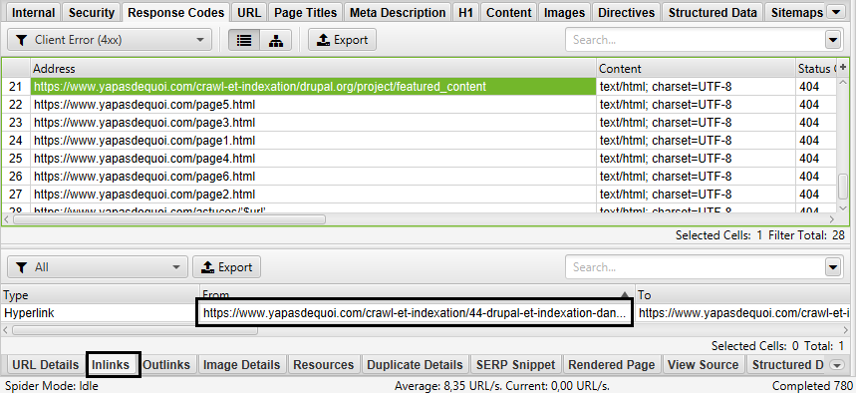
Figure 11 – retrouver le chemin qui permet d’arriver à une page en 404
Une fonctionnalité bien pratique de Screaming Frog vous permettra en un clin d’œil de retrouver tous les chemins pouvant mener à une page via un export spécifique. Pour cela, il est nécessaire de générer un export en sélectionnant l’URL dont on veut connaitre le parcours permettant d’y accéder grâce à la fonction « Crawl Path Report » :
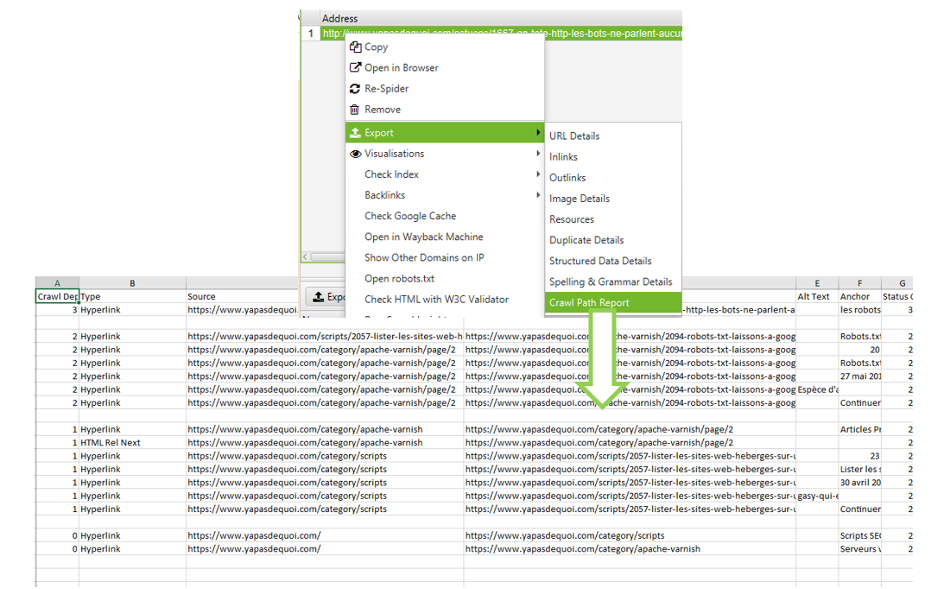
Duplication de contenu
En Juillet dernier, le crawler s’est doté d’une nouvelle fonctionnalité, lui permettant d’analyser le contenu des pages, pour en déterminer le taux de similarité. Mais avant cela, voyons comment utiliser de façon plus fine la duplication au niveau des titres.
Balise <title>
Via l’onglet « Title », nous pouvons être renseigné sur les problématiques liées aux titres des pages. Bien que certains filtres puissent avoir un intérêt mineur (title same as H1), il sera très aisé de repérer les titres qui :
- Sont absents (Missing) ;
- Ont peu de contenu (below 30 caracters) ;
- Dupliqués (Duplicate).
Au sujet du contenu dupliqué, un nombre important de pages peut parfois remonter à cause de la pagination :
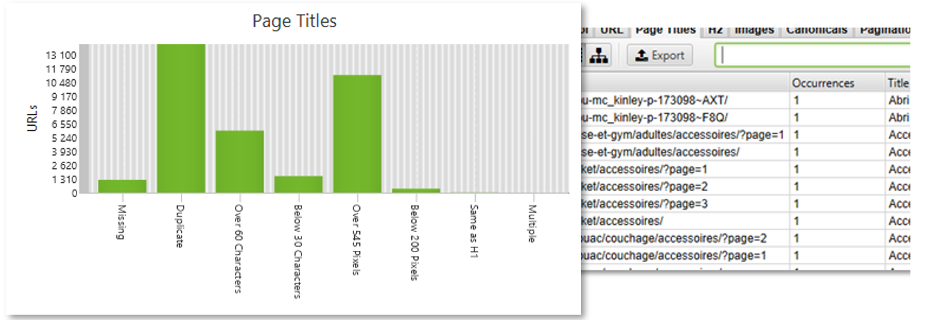
Figure 12 – Problèmes détectés sur la balise <title>
Cette duplication peut donc paraître « logique », Google arrivant maintenant à mieux gérer la pagination qu’auparavant. Mais ces titres dupliqués rendent plus difficile l’analyse, en rendant moins visible les autres problématiques de duplication.
Il est possible via le champ de recherche d’utiliser des expressions régulières afin de filtrer de façon précise certaines URL. Ainsi, pour afficher les titres considérés comme dupliqués, à l’exception de la pagination dans cet exemple, il faudra utiliser l’expression régulière suivante pour afficher toutes les URL qui ne contiennent pas « page= » : ^((?!page=).)*$
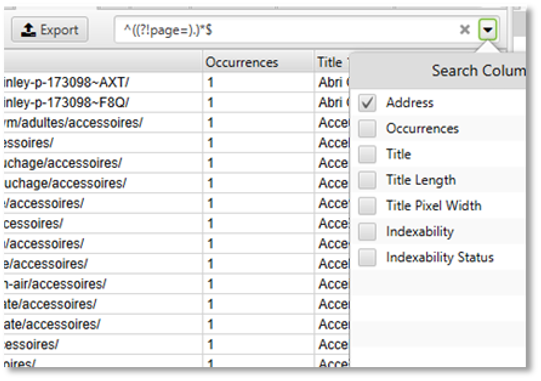
Figure 13 – filtre d’URL via les expressions régulières
Si le crawl contient un nombre important d’URL, il est recommandé de ne cibler que les champs concernés pour accélérer la recherche. Grâce à ce champ, on pourra isoler d’autres problématiques de contenu dupliqué, comme des produits ayant le même titre (mais étant de couleur différente).
Analyse du contenu
La duplication de contenu ne passe pas que par des titres, mais aussi par le contenu d’une page. Grâce à l’onglet « Content », il sera possible d’identifier les pages similaires mais pouvant avoir un titre différent. Cette fonctionnalité très efficace, demande juste une configuration préalable :
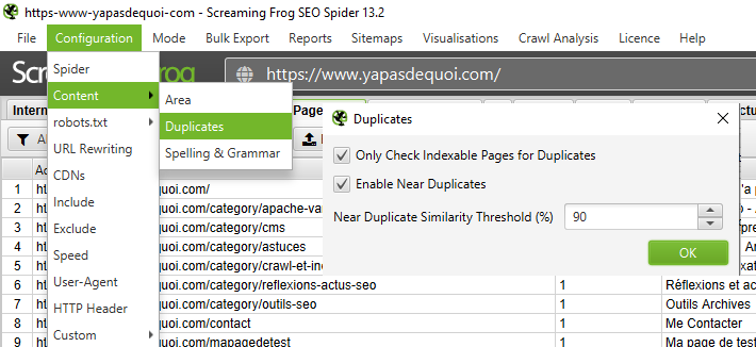
Figure 14 – Analyse du contenu dupliqué
Il est nécessaire de paramétrer le seuil du taux de similarité : en fonction des typologies de sites, on pourra faire varier ce seuil de 60% à 90% (ceci est un ordre de grandeur). Mais un problème se pose malgré tout : d’une page à l’autre, de nombreux éléments sont communs (menu, header, footer, colonne latérale, etc). Ces éléments qui sont identiques de page en page, peuvent faire augmenter le taux de similarité entre les pages d’un site, et donc fausser les analyses.
Heureusement, l’outil dispose d’une fonctionnalité qui permet de ne pas tenir compte de certains éléments HTML dans l’analyse du taux de similarité. Cela nous permettra donc de se concentrer sur le contenu central de la page, et ainsi de détecter des pages pouvant avoir des titres différents, mais un contenu dupliqué.
Cette fonction nommée « Content area » est accessible dans le menu « Configuration > Content > «Area » :
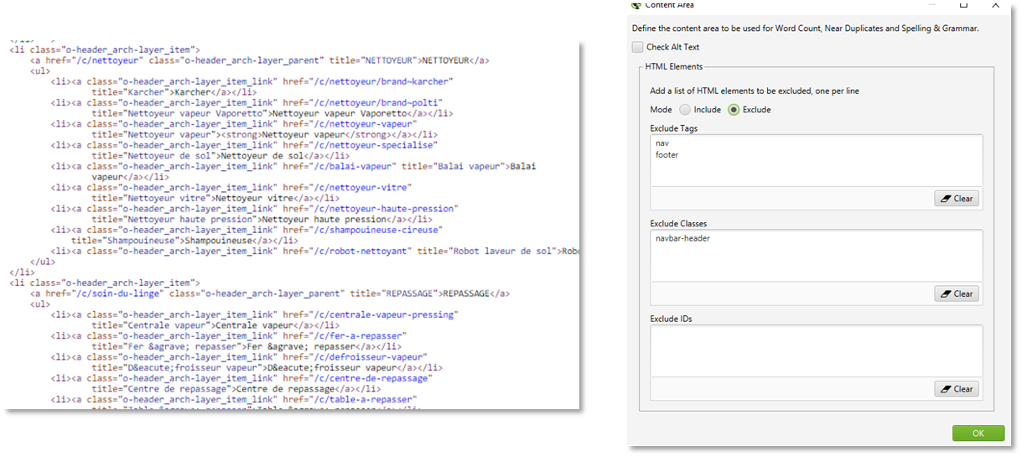
Figure 15 – Exclusion de certains blocs dans le calcul de la similarité
Il est possible de ne pas tenir compte de l’ensemble d’un bloc HTML (ex : « Exclude tag » <nav>, <footer>, <aside>), mais également d’autres balises en fonction de leur classe CSS ou de leur ID. Pour une balise <div> qui aurait comme classe « navbar-header » (<div class=navbar-header>), il suffira d’ajouter le nom de la classe dans le champ réservé à cet effet.
Une fois le crawl lancé, on retrouvera les résultats de l’anaylse relative à la similarité dans l’onglet « Content » :
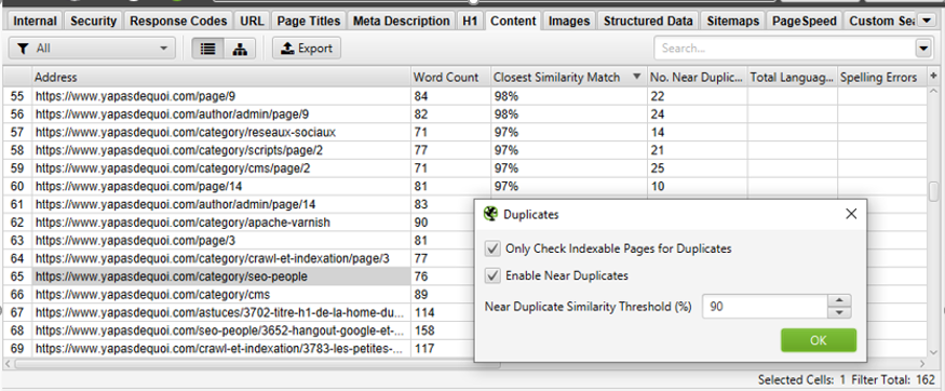
Figure 16 – Analyse de la duplication par rapport au contenu central des pages
Pour chaque URL, Screaming Frog indiquera le taux de similarité le plus élevé dans la colonne « Closest similarity match », et le nombre de contenus concernés dans la colonne « No. Near Duplicate ».
Une fois l’URL sélectionnée, le détail est disponible dans le volet inférieur via l’onglet « Duplicate details ». On pourra ainsi découvrir les principales différences entre deux pages identifiées comme similaires, et mener les actions nécessaires pour limiter cette duplication (fusion de pages, réécriture du contenu, désindexation, etc.).
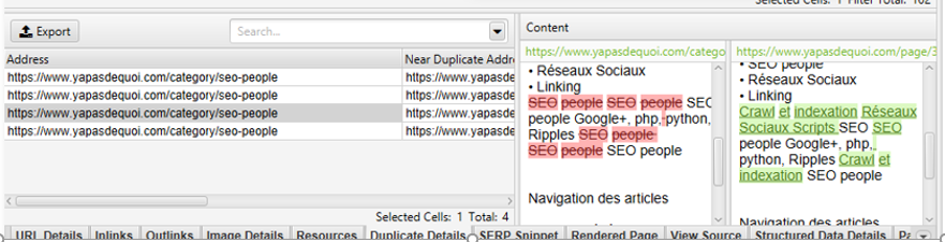
Figure 17 – Comparaison des différences entre 2 pages
D’autres fonctions d’analyse le mois prochain 🙂
Le crawler Screaming Frog offre de nombreuses possibilités d’analyse, qui doivent cependant être couplées à diverses connaissances SEO, afin d’en interpréter correctement les données.
Nous aborderons le mois prochain les outils de visualisations proposés par ce crawler, ainsi des fonctions d’analyses comparatives, pour identifier des URL orphelines (qui n’auraient pas été trouvées lors du crawl, mais qui existerait par ailleurs…). Nous n’en n’avons pas fini avec Screaming Frog… Bon crawl !

![]() Aymeric Bouillat, Consultant SEO senior chez Novalem (https://www.novalem.fr/)
Aymeric Bouillat, Consultant SEO senior chez Novalem (https://www.novalem.fr/)















5
5
4.5
Article super intéressant !
J’ai toujours l’impression de découvrir une nouvelle fonctionnalité avec Screaming frog 🙂
5