
Google utilise des robots pour explorer un site web de la façon la plus efficace possible. Mais il limite ses ressources de façon différente pour chaque site web. Il est donc important d’affiner ce travail, en montrant à Googlebot vos meilleures pages en priorité et en faisant le “ménage” dans votre arborescence pour séparer le bon grain de l’ivraie. Voici donc une somme de conseils bien utiles pour optimiser votre budget crawl pour les moteurs de recherche…
 Par Daniel Roch
Par Daniel RochLa notion de « crawl budget » est importante en référencement naturel, et c’est un sujet de plus en plus abordé dans la communauté des référenceurs en France et dans le monde. Le souci principal est que cette notion est parfois assez vague.
Nous allons donc voir en détail en quoi consiste ce « budget crawl » chez Google, son impact réel sur le référencement naturel d’un site et surtout comment en tirer profit dans une stratégie SEO.
Qu’est-ce que le crawl ?
Commençons par le départ : qu’entend-on par crawl exactement ?
Pour pouvoir proposer des résultats aux internautes, Google doit avant tout connaître le détail des pages de chaque site. Pour cela, il a développé des robots qui lui permettent de parcourir le Web, c’est-à-dire de faire ce fameux crawl, et donc l’exploration des sites web, pages par pages. Ses robots s’appellent GoogleBot, et le moteur de recherche en a créé plusieurs en fonction du type de contenu ou de résultat qu’il avait besoin de trouver et de proposer aux internautes. On retrouve ainsi :
- GoogleBot : pour la plupart des contenus web ;
- Googlebot-News : pour crawler des URL pour les résultats de type « actualité » ;
- GoogleBot-Image : pour crawler des URL de type Image ;
- GoogleBot-Video : pour crawler des URLde type Vidéo ;
- Mediapartners-Google : pour les sites utilisant Adsense pour générer des revenus publicitaires ;
- Adsbot-Google : pour les sites utilisant Adwords pour attirer du trafic supplémentaire ;
- Etc.
Source : https://support.google.com/webmasters/answer/1061943?hl=fr
Ce crawl s’effectue en quasi temps réel. Google parcourt ainsi des millards de pages par jour(20 milliards de sites quotidiennement) afin de proposer des résultats pertinents aux internautes. Vous pouvez d’ailleurs constater vous-même le crawl de Google sur votre site avec le menu « Exploration > Statistiques sur l’exploration » de la Search Console de Google (https://www.google.com/webmasters/tools/).
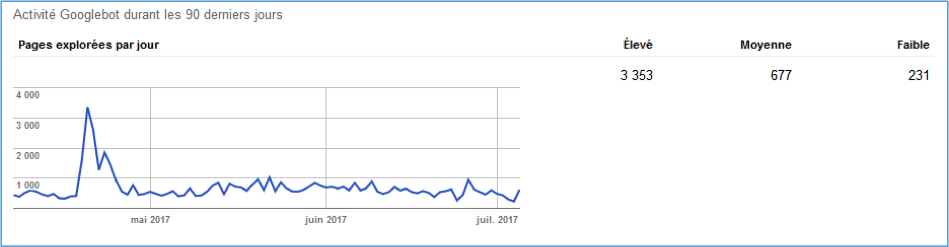
Fig. 1. Des statistiques sur le crawl de Google sur votre site
La notion de budget de Crawl chez Google
En Janvier 2017, Google a voulu clarifier le concept de « budget de crawl » car de nombreux sites parlaient de ce concept mais n’avaient tous pas tous une définition commune (source). Derrière ce terme, il existe en réalité deux aspects différents :
![]() Daniel Roch
Daniel Roch
Consultant WordPress, Référencement et Webmarketing chez SeoMix (http://www.seomix.fr)














4.5