
 Le contenu dupliqué sur Internet est un problème aussi vieux comme le Web lui-même. Une facilité absolue de copie (voire de pillage) de contenu propre à l’espace web multipliée par des constellations de solutions techniques non-optimisées comme les paramètres de tracking ou les erreurs humaines engendre des milliards de pages doublons à côté des pages déjà existantes. Ceci en fait une des tâches prioritaires à gérer par les moteurs de recherche. Et comme d’habitude, ce que veut Google se répercute inévitablement sur le travail des responsables SEO. Le mois dernier, nous avons passé en revue les différents types de contenus dupliqués, les algorithmes de détection et les particularités de traitement du contenu dupliqué par Google. Ce mois-ci, nous abordons les méthodes et outils permettant de l’identifier et bien sûr de le corriger.
Le contenu dupliqué sur Internet est un problème aussi vieux comme le Web lui-même. Une facilité absolue de copie (voire de pillage) de contenu propre à l’espace web multipliée par des constellations de solutions techniques non-optimisées comme les paramètres de tracking ou les erreurs humaines engendre des milliards de pages doublons à côté des pages déjà existantes. Ceci en fait une des tâches prioritaires à gérer par les moteurs de recherche. Et comme d’habitude, ce que veut Google se répercute inévitablement sur le travail des responsables SEO. Le mois dernier, nous avons passé en revue les différents types de contenus dupliqués, les algorithmes de détection et les particularités de traitement du contenu dupliqué par Google. Ce mois-ci, nous abordons les méthodes et outils permettant de l’identifier et bien sûr de le corriger.
 Le contenu dupliqué sur Internet est un problème aussi vieux comme le Web lui-même. Une facilité absolue de copie (voire de pillage) de contenu propre à l’espace web multipliée par des constellations de solutions techniques non-optimisées comme les paramètres de tracking ou les erreurs humaines engendre des milliards de pages doublons à côté des pages déjà existantes. Ceci en fait une des tâches prioritaires à gérer par les moteurs de recherche. Et comme d’habitude, ce que veut Google se répercute inévitablement sur le travail des responsables SEO. Le mois dernier, nous avons passé en revue les différents types de contenus dupliqués, les algorithmes de détection et les particularités de traitement du contenu dupliqué par Google. Ce mois-ci, nous abordons les méthodes et outils permettant de l’identifier et bien sûr de le corriger.
Le contenu dupliqué sur Internet est un problème aussi vieux comme le Web lui-même. Une facilité absolue de copie (voire de pillage) de contenu propre à l’espace web multipliée par des constellations de solutions techniques non-optimisées comme les paramètres de tracking ou les erreurs humaines engendre des milliards de pages doublons à côté des pages déjà existantes. Ceci en fait une des tâches prioritaires à gérer par les moteurs de recherche. Et comme d’habitude, ce que veut Google se répercute inévitablement sur le travail des responsables SEO. Le mois dernier, nous avons passé en revue les différents types de contenus dupliqués, les algorithmes de détection et les particularités de traitement du contenu dupliqué par Google. Ce mois-ci, nous abordons les méthodes et outils permettant de l’identifier et bien sûr de le corriger.Comment identifier le contenu dupliqué ?
Des multiples méthodes et outils, gratuits comme payants, sont à notre disposition pour identifier le contenu dupliqué.
Opérateurs de recherche de Google
C’est probablement la solution la plus simple et efficace, car elle ne demande pas de recourir aux outils spécialisés : prendre une séquence de 6-10 mots du texte, l’encadrer dans les guillemets (droits) et la saisir dans le champ de recherche de Google. Si notre site n’est pas positionné 1er, Google ne nous considère pas comme source et inévitablement dégrade en visibilité.
Les raisons peuvent être très variées et doivent dans ce cas être recherchées :
- Le texte que nous avons utilisé, n’était pas original au départ, mais copié d’une autre source.
- Notre texte est original, mais a été repris par un autre site (sans ou avec une mauvaise volonté).
- Il y a des problèmes d’accessibilité de notre page ce qui résulte au fait que Google préfère en choisir une autre plus stable.
- Notre site manque fortement en autorité et c’est le plus fort qui est sélectionné par Google.
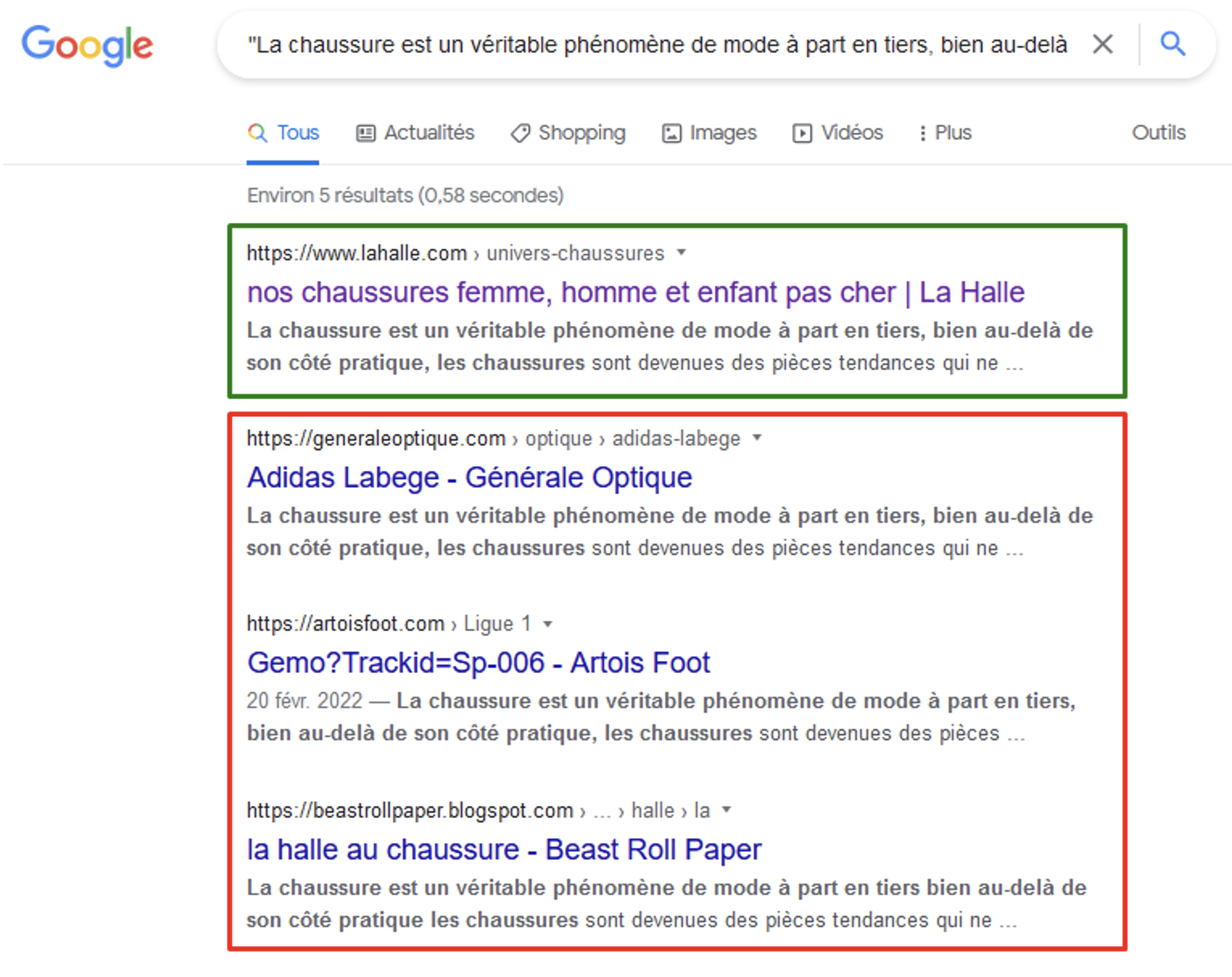
Le texte publié sur la page « Chaussures » de La Halle se retrouve en 1ère position sur la 1ère phrase.
3 autres sites auraient probablement copié le texte, néanmoins La Halle en est toujours considéré comme source.
En associant le passage cible dans les guillemets avec l’opérateur « site : », nous pouvons identifier des duplications internes :
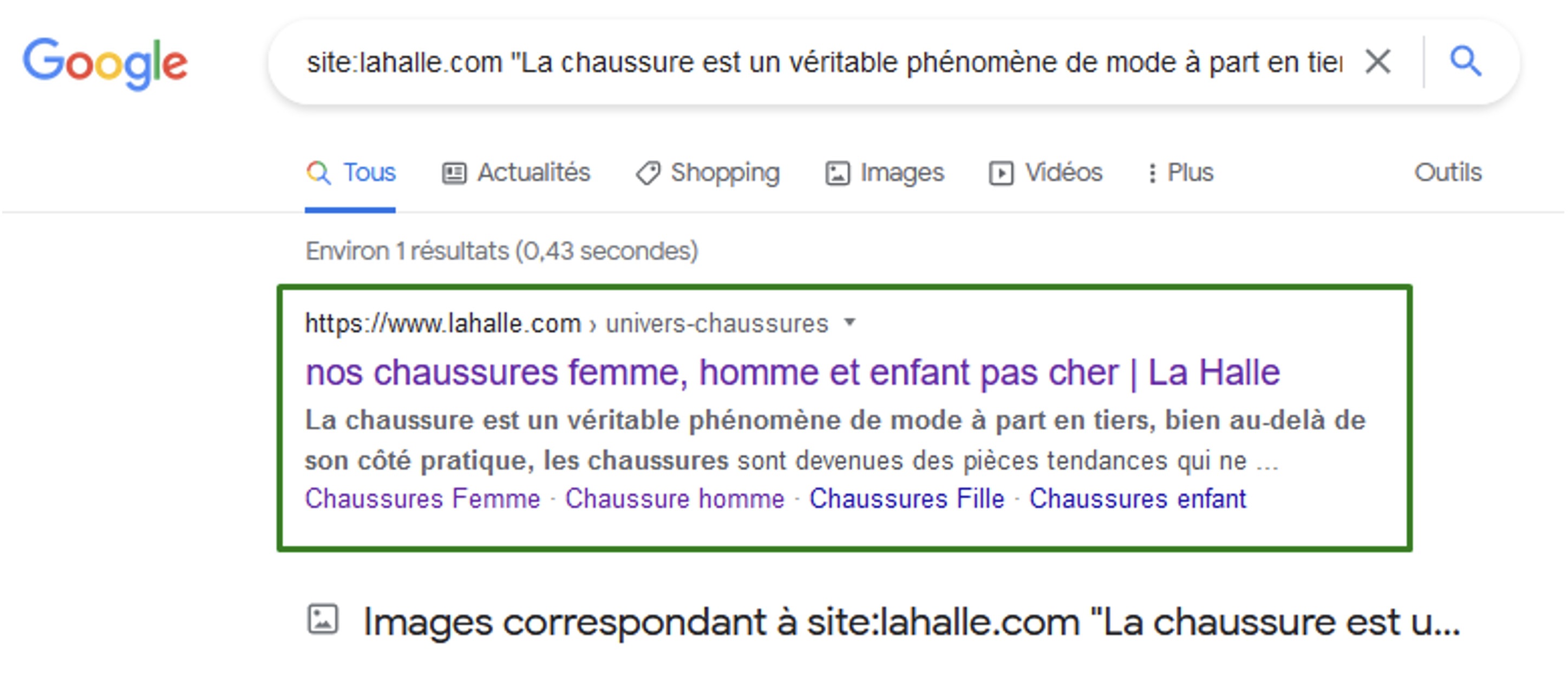
Sur la phrase cible au sein du domaine lahalle.com, une seule page est affichée :
il n’y a pas d’autres utilisations du texte sur d’autres pages du site.
Google Search Console
Le rapport de couverture de la Search Console depuis les dernières mises à jour affiche les détails sur les pages en double, notamment les erreurs possibles d’utilisation de l’attribut rel=canonical :
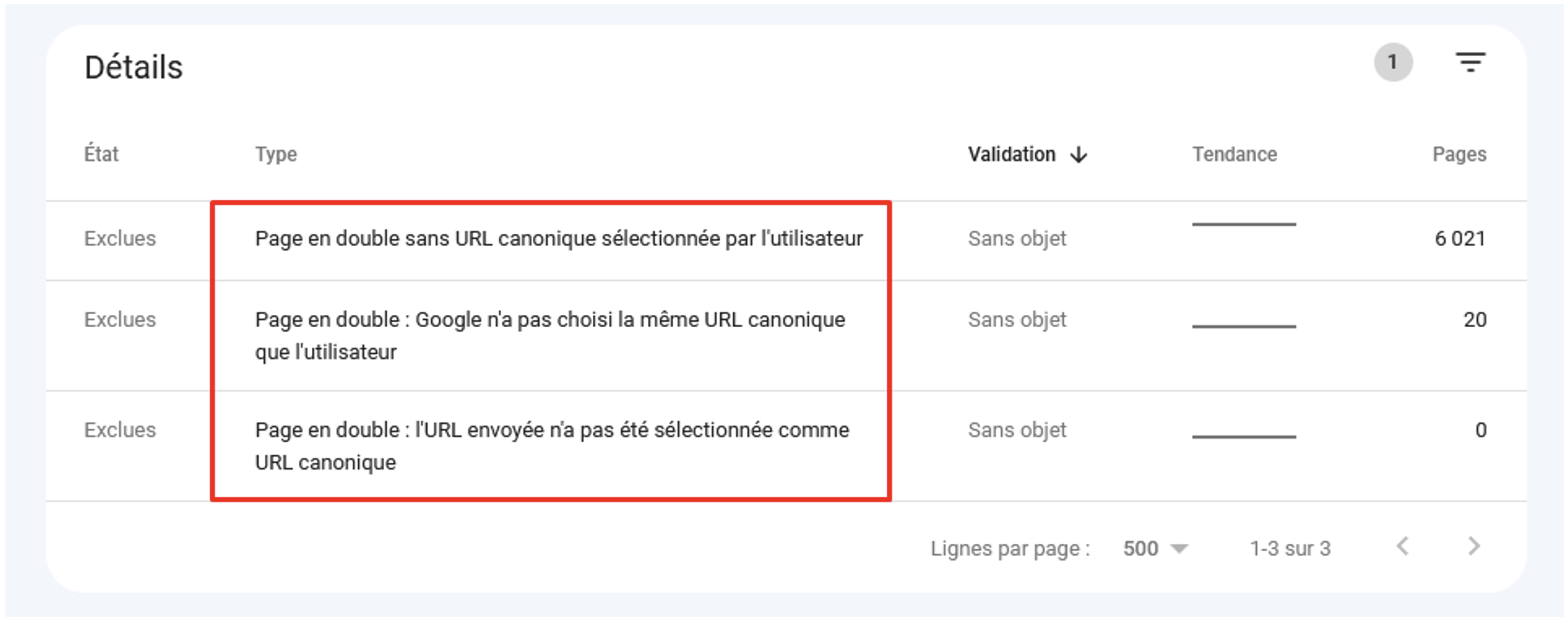
Cas de contenus en double signalés par la Search Console (Couverture > Pages exclues).
Pour 20 pages, Google a préféré ne pas respecter l’attribut rel=canonical dans le code source.








![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-527x297.png)
![Pourquoi vous continuez de produire du contenu… pour rien [Partie 1] - Killian Le Moal](https://www.reacteur.com/content/uploads/2026/05/2026-05-reacteur-killian-le-moal-190x190.png)






5